Amazon - Website
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Identificare e localizzare i documenti in reteWorld Wide Web, come sappiamo, è costituito da una collezione di documenti, ciascuno dei quali è formato da uno o più oggetti digitali archiviati, sotto forma di file, sugli host di Internet. Affinché tali oggetti siano individuabili e accessibili da un determinato user agent (di norma un browser) o da una applicazione server (ad esempio il modulo spider di un motore di ricerca), è necessario un adeguato sistema di identificazione e localizzazione delle risorse on-line, esattamente come i file archiviati nelle memorie di massa di un singolo computer sono gestiti dal file system del sistema operativo. Di fatto tutti i protocolli in uso su Internet sono dotati di un qualche sistema interno per individuare e localizzare le risorse: in termini tecnici possiamo dire che ogni protocollo individua un insieme di oggetti che possono essere raggiunti associando loro un nome o un indirizzo. I nomi o indirizzi usati da un protocollo sono validi solo nell'ambito delle risorse accessibili mediante il protocollo stesso: tale ambito viene definito spazio dei nomi. Ogni protocollo dunque ha uno schema di denominazione che individua uno spazio dei nomi. Se però, come avviene con il Web, un sistema può o deve accedere a risorse collocate in spazi diversi, si rende necessaria la creazione di uno spazio universale dei nomi e degli indirizzi, che permetta di identificare ogni risorsa astraendo dai requisiti tecnici di ogni singolo protocollo. Tanto più che tale spazio astratto dei nomi rimarrebbe valido anche nel caso in cui fosse modificato il modo in cui un protocollo accede alle risorse: basterebbe una modifica all'algoritmo che dal nome o indirizzo universale porta alla stringa di localizzazione effettiva del protocollo. Lo stesso potrebbe dirsi per la creazione di nuovi protocolli. Un membro dell'insieme di nomi o indirizzi in tale spazio universale viene definito Universal Resource Identifier (URI). Ogni URI è suddivisa in due parti principali: uno specificatore di schema seguito da una stringa di identificazione dell'oggetto (path), la cui forma è determinata dallo schema (a sua volta funzione del protocollo cui è associato). Le due parti sono separate dal simbolo ':' (due punti): schema : path. Se lo schema individua uno spazio dei nomi o degli indirizzi organizzato gerarchicamente, esso può essere rappresentato da una serie di sottostringhe separate dal simbolo '/' (barra in avanti) il cui verso va da destra a sinistra. Alcuni schemi permettono di individuare anche parti di un oggetto. In tale caso la stringa che identifica tale parte (identificatore di frammento) viene posta alla estremità destra del path preceduta dal simbolo '#' (cancelletto). Al momento l'unica forma di URI che viene effettivamente utilizzata è la Uniform Resource Locator (URL). Una URL è una forma di URI che esprime l'indirizzo (ovvero la collocazione reale) di un oggetto accessibile mediante uno dei protocolli attualmente in uso su Internet. Per risolvere una serie di problemi legati alla natura delle URL, da alcuni anni è in fase di sviluppo una nuova forma di URI, denominata Universal Resource Name (URN). Una URN, a differenza di una URL, esprime il nome di un oggetto in un dato spazio dei nomi indipendentemente dalla sua locazione fisica. Uniform Resource Locator (URL)Le Uniform Resource Locator (URL), come detto, sono un sottoinsieme del più generale insieme delle URI. Esse codificano formalmente l'indirizzo di ogni risorsa disponibile su Web in modo astratto dagli effettivi algoritmi di risoluzione implementati in ciascun protocollo. Allo stato attuale le URL sono l'unico sistema di identificazione e localizzazione delle risorse di rete effettivamente utilizzato, sebbene ciò determini una serie di problemi sui quali ci soffermeremo nel prossimo paragrafo. La sintassi di una URL, basata naturalmente su quella delle URI, si articola in tre parti:
Di conseguenza una URL ha la seguente forma generale (le parti tra parentesi quadre sono opzionali):
Un esempio di URL per una risorsa Web, è il seguente:
Naturalmente ogni singolo schema di indirizzamento può presentare delle varianti a questa forma generale. Gli schemi registrati e attualmente implementati (corrispondenti ai vari protocolli in uso su Internet) sono i seguenti:
Per gli schemi http, ftp, file e gopher, la sezione del path di una URL ha una struttura gerarchica che corrisponde alla collocazione del file dell'oggetto referenziato nella porzione di file system visibile dal server. Ad ogni server infatti viene assegnato uno spazio sulla memoria di massa che inizia da una data directory (la root del server) e comprende tutte le sue sub-directory. La sezione del path di una URL seleziona la root del server mediante il primo simbolo '/' dopo l'indirizzo dell'host, e le successive subdirectory con i relativi nomi separati da simboli '/'. Ad esempio, se la root di un server HTTP sul file system ha il path '/user/local/httpd/htdocs', la URL 'http://www.foo.it/personal/ciotti/index.html' si riferirà al file '/user/local/httpd/htdocs/personal/ciotti/index.html'. Con lo schema http è possibile usare delle URL relative, che vengono risolte estraendo le informazioni mancanti dalla URL del documento corrente. Gli schemi 'mailto' e 'news' hanno una sintassi parzialmente diversa da quella generale che abbiamo visto sopra. Per la precisione una URL che si riferisce ad un indirizzo di posta elettronica si presenta in questa forma: mailto:identificatore_utente@identificatore.host Ad esempio: mailto:ciotti@uniroma1.it Lo schema per i messaggi su server NNTP ha invece la seguente sintassi: news:nome_newsgroup[:numero_messaggio] Ad esempio: news:comp.text.xml:1223334 Si noti che a differenza degli altri schemi che indicano una locazione assoluta della risorsa, valida ovunque, lo schema news è indipendente dalla collocazione, poiché seleziona un messaggio che ogni client dovrà reperire dal suo server locale. La sintassi delle URL può essere utilizzata sia nelle istruzioni ipertestuali dei file HTML, sia con i comandi che i singoli client, ciascuno a suo modo, mettono a disposizione per raggiungere un particolare server o documento. � bene pertanto che anche il normale utente della rete Internet impari a servirsene correttamente. Uniform Resource NameUne delle esperienze più comuni tra gli utilizzatori abituali di World Wide Web è la comparsa di un messaggio che annuncia l'impossibilità di accedere ad una data risorsa quando si attiva un link ipertestuale o si digita una URL nella barra degli indirizzi del browser. Che cosa è avvenuto? Semplicemente che il file corrispondente non si trova più nella posizione indicata dal suo indirizzo. Che fine ha fatto? Può essere stato spostato, cancellato, rinominato. Il fatto è che i riferimenti in possesso dell'utente non gli permettono più di accedere al suo contenuto. Un'esperienza simmetrica è la scoperta che il contenuto di un certo documento, di cui magari si era inserita la URL nell'elenco dei bookmark, è cambiato. Anche in questo caso la causa del problema è molto semplice: al file 'xyz.html', pur conservando lo stesso indirizzo, è stato cambiato il contenuto. Alla radice di queste spiacevoli esperienze c'è uno dei limiti più importanti della attuale architettura di World Wide Web: il sistema di assegnazione dei nomi alle risorse informative sulla rete, e il modo in cui queste vengono localizzate. Come sappiamo, attualmente queste due funzioni sono svolte entrambe dalla URL di un documento. Il problema fondamentale è che la URL fornisce un ottimo sistema di indirizzamento (ovvero indica con molta efficienza la posizione di un oggetto sulla rete), ma un pessimo schema di assegnazione di nomi. La fusione delle funzioni di indirizzamento e di identificazione delle risorse in una unica tecnologia si rivela un sistema inadeguato in molti altri settori. A titolo di esempio: introduce grossi problemi nello sviluppo di applicazioni di information retrieval sulla rete; rende molto difficile la citazione, il riferimento e la catalogazione bibliografica dei documenti presenti in rete; non permette lo sviluppo di sistemi di versioning, ovvero sistemi che tengano traccia dell'evoluzione dinamica di un documento, conservandone le versioni successive; complica la gestione del mirroring, ovvero la creazione e l'allineamento di molteplici esemplari di un medesimo documento. Lo sviluppo di un efficiente sistema di distribuzione dell'informazione su rete geografica richiede dunque un potente e affidabile sistema di identificazione delle risorse informative. Per rispondere a questa esigenza, vari enti e organizzazioni che si occupano dello sviluppo degli standard su Internet hanno proposto la creazione di un nuovo tipo di URI, denominate Uniform Resource Name (URN). In realtà con questa sigla vengono indicate una serie di tecnologie, ancora in fase sperimentale, nate in ambiti diversi e caratterizzate da diversi approcci e finalità immediate. Nell'ottobre del 1995, in una conferenza tenuta alla University of Tennessee, i vari gruppi interessati hanno definito un sistema di specifiche unitarie. La convergenza prevede la compatibilità tra le varie implementazioni, pur garantendo la coesistenza di ognuna di esse. Dal 1996 la IETF, che si occupa della definizione degli standard per Internet, ha creato un gruppo di lavoro sugli URN. Chi è interessato ad approfondire gli aspetti tecnici e gli sviluppi in corso può consultare le pagine Web di questa commissione, il cui indirizzo è http://www.ietf.org/html.charters/urn-charter.html. In questa sede ci limiteremo ad esporre le caratteristiche generali dell'architettura URN. Un URN è un identificatore che può essere associato ad ogni risorsa disponibile su Internet, e che dovrebbe essere utilizzato in tutti i contesti che attualmente fanno uso delle URL. In generale, esso gode delle seguenti caratteristiche:
Per risorsa si intende il 'contenuto intellettuale' di un documento (testo, immagine, animazione, software, ecc.), o una sua particolare presentazione: ad esempio, ogni versione di un documento in un dato formato può avere un URN. Ciascuna risorsa individuata da un URN può essere disponibile in molteplici copie, distribuite su diversi luoghi della rete: conseguentemente ad ogni URN possono corrispondere molteplici URL. Il processo di determinazione delle URL di una risorsa a partire dalla sua URN viene definito 'risoluzione'. I nomi vengono assegnati da una serie di autorità indipendenti, dette naming authority, che garantiscono la loro unicità e permanenza. A ogni naming authority corrisponde almeno un Name Resolution Service, ovvero un sistema software che effettua la risoluzione del nome [96]. I problemi che si cerca di risolvere attraverso l'introduzione degli URN sono molto rilevanti, anche se, allo stato attuale, non esiste nessuna implementazione pubblica dell'architettura URN. I processi di standardizzazione, come al solito, sono molto lenti, specialmente in un ambiente decentralizzato come Internet. Il consenso necessario alla introduzione di una tecnologia completamente nuova richiede il concorso di molti soggetti, e non di rado impone agli attori commerciali notevoli investimenti nella progettazione o modifica dei prodotti software. L'introduzione delle URN è, comunque, tra gli obiettivi nell'agenda del progetto Internet 2, che coinvolge alcune grandi università statunitensi nella progettazione della rete del prossimo futuro. Nel frattempo, è stato sviluppato un sistema che offre un'ottima approssimazione delle funzionalità di identificazione univoca dei documenti sulla rete. Si tratta delle Persistent URLs (PURLs), non casualmente messe a punto nell'ambito bibliotecario. Il sistema infatti nasce come progetto di ricerca sponsorizzato dalla OCLC, consorzio internazionale di biblioteche, di cui abbiamo parlato nel capitolo 'Le biblioteche in rete'. Il sistema PURLs, come indica il nome, si basa sull'attuale meccanismo di indirizzamento dei documenti su Web e dunque non richiede alcuna modifica negli attuali browser. In effetti una PURL è, sia dal punto di vista funzionale sia da quello sintattico, una normale URL, e può essere utilizzata negli stessi contesti (all'interno dei file HTML, nelle finestre dei browser, ecc). Questa ad esempio, rimanda a un documento introduttivo sul tema: http://purl.oclc.org/OCLC/PURL/SUMMARY. Anziché puntare direttamente verso la risorsa indirizzata, una PURL punta a uno speciale server che ospita un sistema di risoluzione (PURL resolution service): nell'esempio il servizio ha l'indirizzo 'purl.oclc.org'. Quest'ultimo, in base al nome della risorsa - nell'esempio /OCLC/PURL/SUMMARY/ - traduce la PURL in una vera e propria URL, e reindirizza il client verso questo indirizzo. Il meccanismo si basa su una normale transazione HTTP, detta redirezione. L'effettiva localizzazione della risorsa viene determinata dinamicamente dal PURL Service. Se un documento registrato presso un sistema di risoluzione PURL viene spostato (o se cambia il nome del file corrispondente), è sufficiente cambiare l'associazione PURL-URL nel database del servizio. La PURL rimane immutata e dunque tutti i riferimenti e i link da qualsiasi parte della rete verso quel documento continuano a funzionare perfettamente. L'aggiornamento delle relazioni deve essere effettuato esplicitamente dai responsabili della manutenzione del PURL Service. � comunque possibile eseguire questa operazione anche da computer remoti, e assegnare permessi di manutenzione per particolari gerarchie di nomi. Il primo PURL Resolution Service è stato attivato dalla OCLC dal gennaio del 1996, e si è dimostrato molto efficiente. Chi desidera vederlo in funzione può indirizzare il suo browser all'indirizzo http://purl.oclc.org. Naturalmente l'efficacia effettiva di questa tecnologia richiede la disseminazione attraverso la rete del maggior numero possibile di PURL server. Per facilitarne la diffusione l'OCLC ha deciso di distribuire gratuitamente il relativo software, che è disponibile sul sito Web indicato sopra. Molte istituzioni, specialmente nell'ambio bibliotecario e accademico, hanno dimostrato grande interesse, e hanno iniziato a sviluppare altri servizi di risoluzione PURL. Il sistema PURL costituisce un importante passo intermedio verso l'architettura URN. Inoltre, è ormai chiaro che la sintassi PURL sarà facilmente traducibile in forma di URN, trasformandola in uno schema di indirizzamento. Dunque coloro che oggi hanno adottato la tecnologia sviluppata dalla OCLC saranno in grado di migrare verso la tecnologia URN senza problemi. Nel frattempo le PURL, appoggiandosi sull'attuale sistema di indirizzamento utilizzato su Internet, hanno il chiaro vantaggio di essere già disponibili, di funzionare perfettamente e risolvere la sindrome da 'risorsa non disponibile'. Dare vita al Web: da HTML Dinamico alle applicazioni distribuiteUna pagina Web di norma è un oggetto statico. Tutti i processi di elaborazione che sono necessari a generarla terminano nel momento stesso in cui essa viene visualizzata nella finestra del browser. Anche nel caso dei documenti dinamici la generazione del documento riposa esclusivamente sul lato server. Tuttavia negli ultimi anni sono state sviluppate diverse tecnologie al fine di dare vita al Web. Alcune di esse, come i plug-in, in realtà adattano i browser ad incorporare oggetti binari il cui formato non rientra tra gli standard del Web. Altre invece puntano ad introdurre delle vere e proprie capacità elaborative all'interno delle pagine Web, mediante l'uso di linguaggi di programmazione molto semplici. Questi 'linguaggi di script' sono in grado di manipolare gli elementi che costituiscono una pagina e di assegnare loro comportamenti in relazioni ad eventi. Grazie a queste tecnologie è possibile realizzare delle pagine Web dotate di comportamenti dinamici e interattivi senza che sia necessario effettuare transazioni HTTP per scaricare nuovi oggetti. Un ulteriore passo in avanti cui si è assistito recentemente è la diffusione di una vera e propria informatica distribuita basata sul Web. In questo caso, più che l'assegnazione di comportamenti dinamici alle pagine Web, si punta alla creazione di veri e propri programmi applicativi client-server, che usano il Web e la sua architettura come ambiente operativo. Alla origine del Web computing vi è senza dubbio la piattaforma Java, sviluppata dalla Sun, che sta determinando una vera e propria rivoluzione nella storia di Internet, e probabilmente dell'intera informatica. Ma non mancano proposte alternative o almeno parallele, come ActiveX, sviluppata dalla Microsoft. Come ci si può immaginare, lo scontro in questa arena tecnologica e al contempo commerciale è molto duro. D'altra parte su questo crinale passa il grosso dello sviluppo commerciale di Internet per i prossimi anni, poiché da esso dipendono sia lo sviluppo del commercio elettronico sia il settore delle Intranet/Extranet. Nei prossimi paragrafi chiuderemo la nostra rassegna sulle tecnologie di World Wide Web gettando uno sguardo proprio verso queste nuove frontiere. I linguaggi di scriptI linguaggi di script hanno iniziato a diffondersi come strumenti di personalizzazione delle applicazioni di office automation da alcuni anni. Si tratta in genere di semplici linguaggi di programmazione interpretati, in grado di manipolare alcuni elementi di un programma o di applicare procedure di elaborazione sui dati e sui documenti digitali da esso gestiti. La diffusione della programmazione ad oggetti e di architetture come OLE e OpenDoc, ha reso questi linguaggi sempre più potenti ed efficienti, fino a sostituire in alcuni casi la programmazione con linguaggi compilati tradizionali. La prima applicazione di un linguaggio di script client-side nel contesto del Web si deve a Netscape, con l'introduzione di Javascript. Si tratta di un linguaggio dotato di una sintassi simile a quella del linguaggio Java (su cui ci soffermeremo a breve) e basato su una parziale architettura a oggetti e su un modello di interazione ad eventi (come gran parte dei linguaggi simili). Successivamente alla sua prima implementazione, Javascript ha subito diverse revisioni, che hanno creato grandi problemi di compatibilità, contribuendo non poco alla balcanizzazione del Web. In particolare i problemi maggiori erano (e in parte sono tuttora) legati alla diversa definizione degli oggetti su cui è possibile agire nei due browser Netscape ed Explorer (che ha integrato un interprete Javascript, pur cambiando il nome al linguaggio in Jscript, sin dalla versione 3). Fortunatamente a mettere ordine in questa situazione è recentemente intervenuta la European Computer Manifacturers Association (ECMA) che ha definito una versione standard di questo linguaggio - la cui diffusione presso gli sviluppatori Web è ormai enorme - denominata ECMAScript. Un secondo linguaggio di script utilizzato nel contesto del Web è VBScript. Si tratta di una sorta di versione semplificata e adattata alla manipolazione di documenti Web del noto linguaggio di programmazione Visual Basic della Microsoft. Naturalmente VBScript viene interpretato esclusivamente da Explorer, e dunque le pagine che lo adottano come linguaggio di script sono in genere collocate su reti Intranet. A parte le differenze di sintassi e i limiti di portabilità, entrambi questi linguaggi condividono funzionalità e modalità di impiego. In generale uno script è un piccolo programma (al limite una sola istruzione) il cui codice viene inserito all'interno di una pagina HTML o collegato ad esso, e interpretato dal browser. La funzione di queste piccole applicazioni consiste nell'introdurre estensioni all'interfaccia di una pagina Web o del browser, come pulsanti che attivano procedure, controllo del formato di dati in un campo di immissione o piccoli effetti di animazione (ad esempio, del testo che scorre nella barra di stato del browser). In questo modo è possibile aumentare le potenzialità interattive di una pagina Web senza ricorrere allo sviluppo di plug-in o di applet Java, attività che richiedono una competenza da programmatore. HTML Dinamico e DOMLa diffusione e l'evoluzione dei linguaggi di script ha reso possibile la creazione di pagine Web interattive e l'inserimento di piccoli effetti grafici dinamici. Ma la capacità di produrre delle pagine Web in grado di modificare totalmente il loro aspetto e la loro struttura senza interagire con il server HTTP per ricevere nuovi oggetti o un documento HTML aggiornato, è stata raggiunta solo con l'introduzione della tecnologia conosciuta con il nome di Dynamic HTML, o più brevemente DHTML. In realtà DHTML non esiste come linguaggio in sé. Almeno non nel senso in cui esiste HTML, CSS o uno dei linguaggi di script. Infatti DHTML è il prodotto della convergenza di una serie di tecnologie già esistenti, mediata da un insieme di regole che permettono di usare i fogli di stile e un linguaggio di script al fine di modificare l'aspetto e il contenuto di una pagina Web al verificarsi di un dato evento (ad esempio il click o lo spostamento del mouse, o il passare di un periodo di tempo). Il risultato consiste nella creazione di pagine Web che possono modificarsi senza essere ricaricate dal server: pagine Web dinamiche, appunto. Le tecnologie alla base di DHTML, per la precisione, sono le seguenti:
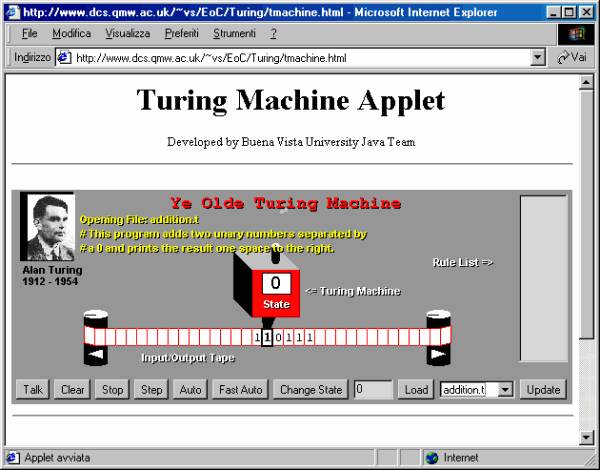
A dire il vero il cuore di DHTML risiede proprio nel DOM. Esso infatti fornisce una descrizione astratta del documento in termini di oggetti, o meglio, di un albero di oggetti che corrisponde alla struttura logica del documento definita dalla sua codifica HTML o XML: ogni elemento del documento ha una sua rappresentazione come oggetto nel DOM. Per ciascun oggetto il DOM specifica alcune proprietà, che possono essere modificate, al verificarsi di un evento (il passaggio o il click del mouse, lo scattare di un dato orario, etc.) mediante una procedura in un determinato linguaggio, e dei metodi, ovvero delle funzioni che ciascun oggetto può effettuare e che possono essere chiamate nell'ambito di un programma. Le utilizzazioni possibili del DOM non sono limitate a DHTML, anche se esso ne rappresenta al momento l'applicazione più diffusa. La tecnologia DHTML ha due vantaggi fondamentali rispetto ai tradizionali sistemi di animazione delle pagine Web (quelli, cioè, che si basano su elaborazioni dal lato server, su plug-in o su programmazione mediante Java o ActiveX). In primo luogo permette di ottenere effetti grafici molto complessi e spettacolari in modo assai semplice. In particolare è possibile avere stili dinamici, che cambiano l'aspetto di una pagina, contenuti dinamici, che ne modificano il contenuto, e posizionamento dinamico, che consente di muovere i componenti di una pagina su tre dimensioni (ottenendo, ad esempio, pagine a strati, o effetti di comparsa e scomparsa di blocchi di testo e immagini). In secondo luogo, permette di conseguire tali effetti con una efficienza e una velocità assai superiori. Quando viene scaricata una pagina dinamica il client riceve tutti i dati che la compongono, anche se ne mostra solo una parte; gli effetti dinamici dunque usano dati collocati nella memoria locale o nella cache e non debbono fare chiamate al server per applicare le trasformazioni alla pagina corrente. Inoltre l'elaborazione di istruzioni DHTML è assai meno onerosa dal punto di vista computazionale rispetto alla esecuzione di codice Java o ad altri sistemi basati su plug-in. Purtroppo a fronte di questi vantaggi DHTML soffre per ora di un grosso limite: le implementazioni di questa tecnologia che sono state proposte da Microsoft e da Netscape sono assai diverse. Così una pagina dinamica che funziona sul browser Netscape non viene letta da Explorer, e viceversa. In particolare la differenza risiede proprio nella implementazione del DOM, cioè nei metodi e nelle proprietà associate ad ogni elemento del documento che possono essere modificate mediante gli script. Questa situazione, che ripercorre la storia già vissuta per HTML negli anni passati, dovrebbe tuttavia essere in via di superamento. Infatti il W3C ha avviato un progetto di standardizzazione del DOM che dovrebbe fornire un insieme di specifiche indipendenti da particolari piattaforme o da particolari linguaggi di script per manipolare gli oggetti che compongono un documento HTML o XML. Nel momento in cui scriviamo la prima fase della standardizzazione è terminata con la pubblicazione delle specifiche DOM level 1 (http://www.w3.org/DOM), che tuttavia ancora non hanno coperto tutti gli aspetti necessari a stabilizzare le implementazioni di DHTML. JavaL'introduzione di Java da parte della Sun Microsystem - una delle maggiori aziende informatiche del mondo [97] - rappresenta probabilmente la più importante innovazione nell'universo della telematica in generale, e di Internet in particolare, dopo la creazione di World Wide Web. Java, che deve il suo nome a una varietà di caffè tropicale, è nato come linguaggio di programmazione ad oggetti, ma si è evoluto fino a divenire una vera e propria piattaforma informatica. Le origini del linguaggio (che inizialmente era stato battezzato Oak) sono molto singolari: esso fu ideato intorno al 1990 da James Gosling per essere incorporato nei microchip che governano gli apparecchi elettronici di consumo. Per molti anni è rimasto un semplice prototipo, finché intorno al 1995 la Sun ha deciso di farlo evolvere, per proporlo come linguaggio di programmazione per Internet. Le caratteristiche che fanno di Java uno strumento rivoluzionario sono diverse. In primo luogo Java implementa pienamente i principi della programmazione orientata agli oggetti (object oriented): in questo tipo di programmazione, i programmi sono visti come società di oggetti, ognuno dotato di capacità particolari, che possono comunicare tra loro e scambiarsi dati; quando un oggetto ha bisogno di una certa operazione che non è capace di effettuare direttamente (ad esempio scrivere i risultati di un calcolo su un file), non deve fare altro che chiedere i servizi di un altro oggetto. Inoltre ogni oggetto può essere derivato da altri oggetti, ereditando da essi proprietà e comportamenti (metodi). Questo paradigma facilita molto l'attività di programmazione sia perché, in fondo, assomiglia abbastanza al nostro modo di rappresentare il mondo, sia perché permette di riutilizzare gli stessi oggetti in molte applicazioni diverse. In secondo luogo, Java è un linguaggio di programmazione che gode di una notevole portabilità. Questa sua caratteristica deriva dalla modalità di esecuzione interpretata dei programmi. L'interprete Java, definito Java Virtual Machine (JVM), fornisce una rappresentazione astratta di un computer che il programma utilizza per effettuare tutte le operazioni di input e output. � poi la JVM che si preoccupa di tradurre tali operazioni in istruzioni macchina per il computer sul quale è installata, comunicando con il sistema operativo o direttamente con il processore, nel caso di macchine basate sulla piattaforma JavaOS (si tratta di macchine che usano direttamente la piattaforma Java come sistema operativo, come alcune versioni di Network Computer). In questo modo un programma scritto in Java può essere eseguito indifferentemente su ogni piattaforma per cui esista una JVM senza subire modifiche. Prima di essere eseguito, tuttavia, esso deve essere sottoposto ad un processo di 'precompilazione'. Il kit di sviluppo Java (Java Development Kit) con cui poter effettuare questa operazione viene distribuito gratuitamente dalla Sun. Per chi è interessato, il sito di riferimento è all'indirizzo Web http://www.javasoft.com [98]. Un'ultima caratteristica importante di Java è il fatto di essere stato progettato appositamente per lo sviluppo di applicazioni distribuite, specialmente con l'uscita delle estensioni JavaBean. Questo significa che un'applicazione Java può essere costituita da più moduli, residenti su diversi computer, in grado di interoperare attraverso una rete telematica. A queste caratteristiche fondamentali se ne aggiunge una ennesima che rende l'integrazione di Java con Internet ancora più profonda: un programma Java può essere inserito direttamente all'interno di una pagina Web. Queste versioni Web dei programmi Java si chiamano applet. Ogni volta che il documento ospite viene richiesto da un browser, l'applet viene inviato dal server insieme a tutti gli altri oggetti che costituiscono la pagina. Se il browser è in grado di interpretare il linguaggio, il programma viene eseguito. In questo modo le pagine Web possono animarsi, integrare suoni in tempo reale, visualizzare video e animazioni, presentare grafici dinamici, trasformarsi virtualmente in ogni tipo di applicazione interattiva. Sappiamo che alcuni browser sono in grado di visualizzare dei file con animazioni o con brani video attraverso la tecnologia dei plug-in. Ma i plug-in sono tutto sommato delle normali applicazioni che vanno prelevate (magari direttamente da Internet) e installate appositamente. Solo allora possono esser utilizzate. E deve essere l'utente a preoccuparsi di fare queste operazioni, con le relative difficoltà. Infine, i plug-in sono programmi compilati per un determinato sistema operativo (e per un determinato browser!), e non funzionano sulle altre piattaforme: un plug-in per Windows non può essere installato su un computer Mac o Unix. Con Java questi limiti vengono completamente superati. Infatti i programmi viaggiano attraverso la rete insieme ai contenuti. Se ad esempio qualcuno sviluppa un nuovo formato di codifica digitale per le immagini, e intende utilizzarlo per distribuire file grafici su World Wide Web, può scrivere un interprete per quel formato in Java, e distribuirlo insieme ai file stessi. In questo modo ogni browser dotato di interprete Java sarà in grado di mostrare i file nel nuovo formato. Inoltre lo stesso codice funzionerebbe nello stesso modo su ogni piattaforma per la quale esistesse un browser dotato di interprete Java. Attraverso l'uso di Java, il potere di 'inventare' nuove funzionalità e nuovi modi di usare Internet passa nelle mani di una comunità vastissima di programmatori, che per di più possono sfruttare l'immenso vantaggio rappresentato dalla condivisione in rete di idee, di soluzioni tecniche, di moduli di programma. Le potenzialità di questa tecnologia hanno naturalmente destato subito una grande attenzione nelle varie aziende che producono browser per Web. Anche in questo caso la più dinamica è stata Netscape, che ha integrato un interprete Java sin dalla versione 2 del suo browser. Attualmente Netscape supporta Java su tutte le piattaforme. Microsoft si è allineata molto presto, integrando Java a partire dalla versione 3 di Explorer - malgrado il gigante di Redmond abbia sviluppato una tecnologia in parte omologa, ma proprietaria, battezzata ActiveX. La diffusione di Java su World Wide Web è stata assai rapida, anche se molte tecnologie concorrenti ne contendono la supremazia. La maggior parte delle applicazioni Java presenti sulla rete sono utilizzate per realizzare animazioni ed effetti grafici; non mancano però applicazioni scientifiche, didattiche e anche commerciali. Se desiderate esaminare sistematicamente i risultati di queste sperimentazioni, potete partire da uno dei molti siti Web che catalogano le applicazioni Java disponibili su Internet: il più noto e completo è Gamelan, all'indirizzo http://www.gamelan.com. In italiano invece vi consigliamo Java Italian site all'indirizzo http://jis.rmnet.it/. Moltissimi degli applet elencati in queste pagine sono di pubblico dominio, e possono essere prelevati, modificati e inclusi all'interno delle proprie pagine Web. Nella figura 131 vediamo un esempio di applet Java eseguito in una finestra di Internet Explorer; si tratta di un programma che simula il funzionamento di una 'macchina di Turing' (lo trovate alla URL http://www.dcs.qmw.ac.uk/~vs/EoC/Turing/tmachine.html) [99].
Un aspetto particolare legato alla tecnologia Java è quello della sicurezza informatica. Per evitare problemi agli utenti, l'interprete del linguaggio è dotato di potenti sistemi di sicurezza, che impediscono ad un programma di interagire direttamente con le componenti più delicate del sistema operativo. In questo modo, dovrebbe essere limitata la possibilità di scrivere e diffondere attraverso la rete pericolosi virus informatici. In effetti, queste protezioni rendono estremamente difficile la progettazione di applet veramente dannosi - in particolare per quanto riguarda azioni come la distruzione dei dati sul nostro disco rigido o simili. Tuttavia, come ci si poteva aspettare, qualcuno ha finito per interpretare questa difficoltà come una vera e propria sfida, e la corsa alla programmazione di quelli che sono stati efficacemente denominati 'hostile applets' è iniziata. Né è mancato qualche risultato: si è visto che, nonostante le precauzioni, un applet Java può riuscire a 'succhiare' risorse dal sistema fino a provocarne il blocco. Il danno effettivo non è di norma troppo rilevante (al limite, basta spegnere e riaccendere il computer), ma naturalmente non va neanche sottovalutato, soprattutto nel caso di un accesso a Internet attraverso grossi sistemi, il cui blocco può coinvolgere altri utenti. Le potenzialità innovative di Java vanno ben oltre l'introduzione di semplici applicazioni dimostrative all'interno delle pagine Web. Un applet infatti è un programma vero e proprio, che può svolgere qualsiasi funzione. Un browser dotato di un interprete Java può dunque eseguire direttamente al suo interno ogni tipo di applicazione, anche le più complesse: database, word processor, foglio di calcolo, programma di grafica, gioco multiutente. Gli sviluppi di questo genere di applicazioni distribuite sono molto promettenti. Non stiamo pensando qui al settore di mercato consumer (ovvero 'casalingo'), almeno a breve termine: sarebbe impensabile scaricare regolarmente dalla rete interi programmi di dimensioni notevoli, e utilizzarli on-line tramite una normale sessione Internet su linea telefonica. Ben diverso il discorso per il settore di mercato aziendale, specialmente nell'ottica della diffusione di tecnologie Intranet, e del Network Computing, su cui torneremo in seguito. Ma se gettiamo lo sguardo oltre l'immediato futuro, il paradigma dell'informatica distribuita e delle Web application ci fornisce un possibile quadro di quello che potrebbe diventare l'informatica sia professionale sia domestica. Al posto di programmi sempre più ipertrofici ed esosi, il nostro computer ospiterà un sistema di navigazione, del quale faranno parte più moduli software scritti in Java, capaci di essere usati su più piattaforme e di collaborare fra loro. Alcuni di questi moduli (ad esempio quelli per la visualizzazione delle pagine HTML, o dei mondi VRML) saranno più diffusi e utilizzati da quasi tutti gli utenti; altri (ad esempio quelli per la ricezione selettiva di 'canali' di notizie, di stazioni di Web radio e Web TV, o per la videotelefonia) da settori di pubblico larghi ma non onnicomprensivi; altri ancora (ad esempio moduli specifici per effettuare operazioni borsistiche o bancarie, per l'accesso a database, per la videoscrittura) da gruppi di utenti assai più ristretti. Avremo anche moduli di programma nati per soddisfare le esigenze di una singola azienda o di un gruppo di aziende - nati cioè per essere utilizzati in una rete Intranet o Extranet. Come hanno intuito, anche se in maniera parzialmente diversa, sia Microsoft sia Netscape, questo ambiente di navigazione, capace di eseguire applicazioni Java (Java enabled) e di collegarsi alla rete, finirà per rappresentare il vero sistema operativo del computer che usiamo: per dirla con uno slogan (coniato da Scott McNealy, CEO della Sun) 'la rete come sistema operativo'. Per questo Microsoft, che con Windows detiene la larghissima maggioranza dei sistemi operativi installati, è impegnata nel tentativo di 'assimilare' i moduli di navigazione e la capacità di eseguire al meglio le applicazioni Java all'interno del suo sistema operativo. E per questo Netscape e i molti altri concorrenti di Microsoft sono impegnati nel tentativo di costruire attraverso Java moduli software comuni utilizzabili su macchine diverse e capaci di svolgere molte delle funzioni tradizionalmente attribuite ai sistemi operativi. I due tentativi sono in conflitto? In linea di principio no, ma di fatto sì. Per Microsoft, Java è una necessità, ma anche una minaccia: se i programmi Java si possono usare allo stesso modo su macchine basate su sistemi operativi completamente diversi, viene meno il maggiore incentivo all'uso di Windows - il fatto che si tratti del sistema operativo standard, per il quale la maggior parte dei programmi sono concepiti e sviluppati. Questo spiega perché Microsoft abbia cercato di costruire una versione 'personalizzata' e ottimizzata di Java, integrata il più strettamente possibile con la tecnologia Active X. Se Microsoft può dire che i programmi Java funzionano meglio (più velocemente, con funzionalità più estese e capacità più avanzate) su Windows che altrove, ha vinto la sua battaglia. Ma se i programmi Java funzionassero meglio su Windows che altrove, Java avrebbe perso una delle sue battaglie - probabilmente la principale. La 'guerra dei browser' tra Microsoft e Netscape (nella quale peraltro la Microsoft ha ormai conquistato una posizione di deciso vantaggio) è così diventata solo uno dei fronti di uno scontro di assai più vasta portata. � in questa chiave, ad esempio, che va letta l'adozione da parte di Sun Microsystems, Netscape Corporation, IBM, Apple, Oracle e alcune altre case, del programma 100% pure Java. Si tratta in sostanza di un 'bollino di compatibilità' assegnato alle applicazioni che superano un test automatico destinato a controllare l'uso 'corretto' di Java, e l'utilizzazione solo di componenti e istruzioni standard. ActiveXActiveX è una tecnologia sviluppata dalla Microsoft per introdurre su Web pagine dinamiche e applicazioni interattive. Può essere considerata come la risposta del gigante dell'informatica mondiale sia a Java sia ai plug-in. Infatti ActiveX (che a sua volta si basa su Distributed COM, l'architettura Microsoft per la comunicazione tra oggetti software distribuiti in ambiente di rete) permette di incorporare all'interno delle pagine Web oggetti attivi e di controllarne il comportamento e l'interazione con il browser. Naturalmente il browser deve avere il supporto all'architettura ActiveX per utilizzare gli oggetti, denominati tecnicamente 'controlli' (controls). Per il momento l'unico browser dotato di queste capacità in modo nativo è Microsoft Explorer. Tuttavia anche Netscape Navigator può visualizzare pagine con controlli ActiveX, utilizzando degli appositi plug-in (tra essi ricordiamo ScriptActive, sviluppato dalla Ncompass e distribuito con la formula shareware all'indirizzo http://www.ncompasslabs.com). Un controllo ActiveX può svolgere qualsiasi funzione: interpretare e visualizzare file multimediali, accedere ad un database, collegarsi a un server IRC, fornire funzioni di word processing, fino a divenire un programma vero e proprio con una sua interfaccia utente. Quando il browser riceve una pagina Web che integra dei controlli, li esegue automaticamente, ereditandone i comandi e le funzioni. Un esempio di utilizzazione di ActiveX è il sistema di aggiornamento on-line dei sistemi operativi Windows 98 e 2000.
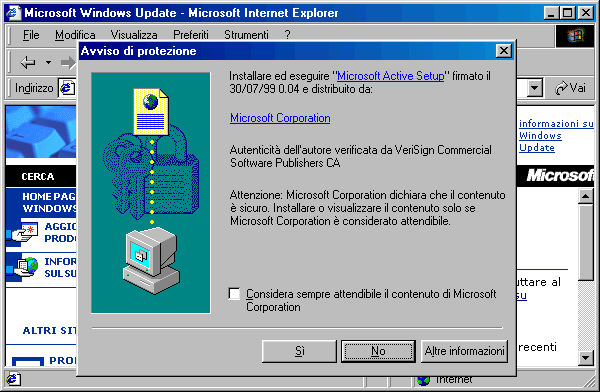
Quando si accede al sito Windows Update, infatti, Explorer scarica un controllo ActiveX (Microsoft Active Setup) che interagisce con il sistema operativo e permette di scaricare e installare gli aggiornamenti direttamente dalle rete, controllando automaticamente l'eventuale rilascio di aggiornamenti critici. Oltre a funzionare nel contesto di pagine Web, gli oggetti ActiveX possono essere eseguiti da ogni applicazione dotata di supporto COM, tra cui si annoverano la maggior parte dei più evoluti programmi per la piattaforma Windows. Chi è abituato ad usare questo sistema operativo avrà notato una stretta somiglianza tra ActiveX e OLE (Object Linking and Embedding), la tecnologia che permette a due programmi in ambiente Windows di comunicare tra loro e di scambiarsi dinamicamente dati e funzioni. In effetti ActiveX è una sorta di cugino giovane di OLE: si basa infatti sulla stessa architettura sottostante, la Component Object Model, ma presenta dei notevoli vantaggi in termini di efficienza e dimensione, in vista del suo uso su ambienti distribuiti. Un software dotato di supporto ActiveX, di conseguenza, è in grado di visualizzare e modificare i documenti prodotti dalle applicazioni Office della Microsoft, e in generale da tutti i programmi che rispondono alle specifiche OLE 2. L'uso di questa tecnologia permette dunque un altissimo livello di integrazione fra le risorse locali e le risorse di rete; e i nuovi programmi Microsoft hanno fra le proprie innovazioni principali proprio la capacità di sfruttare appieno questa integrazione. Con la nuova versione della suite Office, battezzata Office 2000, è possibile non solo salvare tutti i documenti creati con le varie applicazioni della suite in un formato misto HTML/XML, ma anche lavorare su documenti conservati su un server Web (dotato delle opportune estensioni) come se fossero sul disco locale, e inserire nelle pagine Web oggetti creati con le varie applicazioni Office che possono essere aperti, modificati e salvati in rete in modo del tutto trasparente dai rispettivi programmi di origine. Dal punto di vista dell'utente, ActiveX presenta notevoli vantaggi rispetto ai plug-in. La più interessante è l'installazione automatica e la certificazione: quando Explorer riceve una pagina che usa un controllo non presente sul sistema appare una finestra di dialogo che mostra il certificato di garanzia del software e chiede all'utente il permesso di trasferire e installare il modulo; se la risposta è affermativa il controllo viene scaricato e installato automaticamente. I certificati aiutano l'utente a gestire la sicurezza del suo sistema: infatti è possibile configurare Explorer, indicando da quali fonti accettare software e da quali imporre restrizioni, attraverso i comandi di configurazione della protezione. Più articolato è il rapporto tra l'architettura ActiveX e il linguaggio di programmazione Java. In questo caso, tecnicamente parlando, più che di diretta concorrenza si dovrebbe parlare di integrazione. In effetti un controllo in quanto tale può essere visto come l'omologo funzionale di un applet Java - sebbene sia diverso dal punto di vista informatico. Ma ActiveX non coincide con i controlli: anzi è in grado di integrare al suo interno sia controlli sia applet Java e persino di farli interagire. Infatti il supporto Java di Explorer (la Java Virtual Machine) è parte di ActiveX. Questo naturalmente in teoria.
Di fatto i controlli si pongono inevitabilmente come sostituti degli applet, e rientrano nella strategia di sviluppo della Microsoft verso il mondo Internet. Il gigante di Redmond pensa di vincere questa battaglia contando sul fatto che la maggior parte degli sviluppatori e delle software house conoscono molto bene la tecnologia OLE, di cui ActiveX è una semplice evoluzione, e linguaggi di programmazione come C++ e Visual Basic, e sono poco propensi a effettuare transizioni verso un nuovo linguaggio. Inoltre i controlli ActiveX, essendo compilati, sono decisamente più efficienti e veloci nell'esecuzione rispetto ai programmi Java. D'altra parte ActiveX rispetto a Java soffre di una evidente limitazione di portabilità. Infatti mentre il linguaggio sviluppato dalla Sun è nativamente multipiattaforma, per ora la tecnologia Microsoft lo è solo negli annunci. Nella pratica il legame con i sistemi operativi di casa, e in particolare con Windows 95/98 e 2000, è talmente stretto che difficilmente assisteremo ad una apertura reale verso il mondo Unix e Macintosh, e comunque non ci sono dubbi che il cuore dell'evoluzione di ActiveX rimarrà centrato su Windows ed eredi. Note [96] Si noti che l'architettura immaginata per gli URN è molto simile a quella già in funzione per il DNS, tanto che alcuni hanno proposto di unificare i due sistemi. [97] La Sun è specializzata nel settore dei sistemi Unix di fascia medio-alta, in cui detiene la maggiore fetta di mercato. [98] Sono disponibili sul mercato anche diversi ambienti di programmazione integrati commerciali, realizzati dalle maggiori aziende informatiche nel settore dei linguaggi di programmazione. Naturalmente questi sistemi commerciali aggiungono alle funzionalità di base strumenti visuali di programmazione e di controllo (debugging) del codice, e sono rivolti ai programmatori professionisti. [99] Una macchina di Turing, che eredita il nome dal geniale matematico inglese fondatore dell'informatica teorica, è un dispositivo ideale in grado di effettuare qualsiasi processo di calcolo per cui si possa specificare una procedura finita, ovvero composta da un numero finito di passi. La teoria delle macchine di Turing è alla base della scienza dei calcolatori digitali. |

![]()