Amazon - Website



 |
 |
||||||||||
 |
Tecnologie
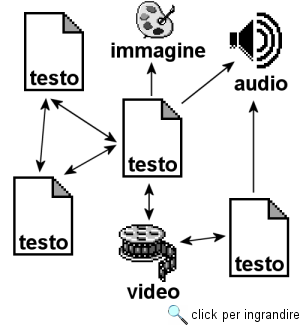
L'architettura del World Wide WebWorld Wide Web tra tutte le applicazioni disponibili su Internet è quella che gode della maggiore diffusione presso gli utenti, e che rappresenta per così dire la 'punta di diamante' della rete. Per moltissimi utenti essa coincide addirittura con Internet. Se questa sovrapposizione, come sappiamo, è tecnicamente scorretta, è pur vero che la maggior parte delle risorse attualmente disponibili on-line si colloca proprio nel contesto del Web. D'altra parte, anche se consideriamo il complesso di innovazioni tecnologiche che negli ultimi anni hanno investito la rete, ci accorgiamo che la quasi totalità si colloca nell'area Web. Per queste ragioni abbiamo ritenuto opportuno dedicare un intero capitolo alla descrizione dell'architettura e dei vari linguaggi e sistemi su cui si basa il suo funzionamento. Come abbiamo già avuto modo di ricordare, l'architettura originaria del Web è stata sviluppata da Tim Berners Lee. Alla sua opera si devono l'elaborazione e l'implementazione dei principi, dei protocolli e dei linguaggi che ancora caratterizzano questa complessa applicazione di rete. Tuttavia, quando fu concepito, il Web era destinato a una comunità di utenti limitata, non necessariamente in possesso di particolari competenze informatiche ed editoriali, e non particolarmente preoccupata degli aspetti qualitativi e stilistici nella presentazione dell'informazione. Per questa ragione nello sviluppo dell'architettura Web furono perseguiti espressamente gli obiettivi della semplicità di implementazione e di utilizzazione. Queste caratteristiche hanno notevolmente contribuito al successo del Web. Ma con il successo lo spettro dei fornitori di informazione si è allargato: nel corso degli anni World Wide Web è diventato un vero e proprio ambiente di editoria distribuita e di fornitura di servizi avanzati. Ovviamente l'espansione ha suscitato esigenze e aspettative che non erano previste nel progetto originale, stimolando una serie di revisioni e di innovazioni degli standard tecnologici originari. Un aspetto di questo processo di innovazione ha riguardato il potenziamento della capacità di gestione e controllo dei contenuti multimediali pubblicati su Web, e dunque dei linguaggi utilizzati per la loro creazione. In una prima fase un ruolo propulsivo in questo processo fu assunto dalle grandi aziende produttrici di browser. Nel corso degli anni '90 tanto Microsoft quanto Netscape, man mano che nuove versioni dei loro browser venivano sviluppate, introducevano innovazioni ed estensioni, al fine di conquistare il maggior numero di fornitori di servizi e dunque di utenti (infatti le nuove caratteristiche, almeno in prima istanza, erano riconosciute e interpretate correttamente solo dai rispettivi browser). Questa corsa all'ultima innovazione, se molto ha migliorato l'aspetto e la fruibilità delle pagine pubblicate su Web, ha rischiato di avere effetti devastanti sulla portabilità e accessibilità dei contenuti on-line13. Qualcuno in passato ha addirittura paventato una balcanizzazione di World Wide Web14. Per ovviare al rischio di una 'babele telematica', ed evitare che le tensioni indotte dal mercato limitassero l'universalità di accesso all'informazione on-line, nel 1994 lo stesso Tim Berners Lee promosse la costituzione del World Wide Web Consortium (W3C)15. Si tratta di una organizzazione no profit ufficialmente deputata allo sviluppo degli standard tecnologici per il Web che raccoglie centinaia di aziende, enti, centri di ricerca e singoli specialisti coinvolti più o meno direttamente nel settore delle tecnologie Web. Il lavoro del W3C si articola per commissioni e gruppi operativi, che producono proposte sotto forma di bozze di lavoro (working drafts). Ogni proposta viene poi sottoposta a un processo di verifica e di revisione, finché non viene approvata dal consiglio generale e diventa una 'raccomandazione' (recommendation), alla quale è possibile far riferimento per sviluppare software. In questi ultimi anni il W3C ha prodotto una lunga e articolata serie di specifiche divenute, o in procinto di divenire, standard ufficiali su Internet. Tutti i materiali prodotti dal W3C sono di pubblico dominio, e vengono pubblicati sul suo sito Web. La maggior parte delle tecnologie di cui parleremo nei prossimi paragrafi è stata elaborata o è tuttora in corso di elaborazione in tale sede. Naturalmente la nostra trattazione si limiterà a fornire delle semplici introduzioni che non pretendono di esaurire i temi trattati. Il nostro scopo è di fornire ai lettori più curiosi e consapevoli alcune nozioni su quello che c'è dentro la scatola, e di suscitare curiosità e stimoli ad approfondire i temi trattati. A tale fine, oltre alla bibliografia, ormai sterminata, sull'argomento, rimandiamo al sito del W3C, il cui indirizzo è http://www.w3.org/, e a quello della IETF, alla URL http://www.ietf.org/; in entrambi i siti è possibile reperire aggiornamenti costanti, documentazione e rapporti sull'attività di innovazione e di standardizzazione. Un secondo aspetto del processo evolutivo del Web e della sua architettura ha riguardato la capacità di fornire applicazioni e servizi avanzati on-line. Un primo passo in questa direzione è stato lo sviluppo di sistemi per la distribuzione di contenuti dinamici e interattivi. Ma negli ultimi anni l'attenzione si è concentrata sulla trasformazione del Web in una vera e propria piattaforma su cui basare lo sviluppo di applicazioni distribuite, denominate Web application services. A questo fine non basta disporre di linguaggi per la descrizione dei contenuti, ma occorrono anche linguaggi di programmazione, piattaforme di sviluppo, interfacce per l'interoperabilità di processi, dati e sistemi in rete. Le ricadute economiche di queste tecnologie potrebbero essere enormi, e non a caso grandi e piccoli attori del settore I&CT (da Microsoft, IBM, Sun e Oracle in giù) hanno investito notevoli somme e risorse in questa direzione. L'affermazione di questo paradigma cambierebbe radicalmente il modo di gestire i sistemi informativi aziendali: invece di acquistare o sviluppare internamente il software e curarne la manutenzione (con tutti i costi connessi), un'azienda potrebbe affittare servizi applicativi da terze parti. Con l'avvento della banda larga anche il mercato consumer potrebbe essere coinvolto. E anche per i sistemi informativi interni il passaggio da un approccio basato sulla presenza di numerose applicazioni autonome residenti sui client a uno basato su servizi applicativi centralizzati accessibili on-line determinerebbe una notevole riduzione del cosiddetto Total Cost of Ownership (costo totale di possesso), oltre che una migliore gestione dell'efficienza e della sicurezza. Infine, alcuni brevi cenni vanno senza dubbio dedicati a quella che potrebbe essere la prossima rivoluzione del Web: il Web Semantico. L'idea di fondo di questa rivoluzione è semplice: dotare i sistemi di gestione delle informazioni in rete della capacità di analizzare il significato di tali informazioni, e dunque di selezionarle o confrontarle in modo semantico o di inferirne conseguenze non esplicitate. Basti pensare al funzionamento attuale dei motori di ricerca: essi si basano in massima parte su un semplice confronto di stringhe di caratteri, e su alcuni semplici trucchi di relevance feedback. Ma se volessimo chiedere (magari in linguaggio naturale) a un motore di ricerca «Dove posso comprare un computer da usare per elaborare grafica 3D a un buon prezzo?» tale meccanismo sarebbe del tutto insufficiente. Infatti il motore di ricerca dovrebbe in primo luogo avere la capacità di analizzare pagine Web in lingue diverse, cercando di associare a diverse stringhe di simboli uno stesso referente; poi dovrebbe avere delle regole per inferire quali caratteristiche tecniche dovrebbe ragionevolmente avere il computer per rispondere alle esigenze del richiedente; poi dovrebbe avere un modo per giudicare sensatamente il rapporto prezzo/prestazioni (ad esempio non dovrebbe scartare un'offerta conveniente solo perché il suo costo è, poniamo, di un euro superiore alla soglia del prezzo 'giusto' calcolata); e infine dovrebbe fornire una risposta, magari articolata e motivata. Dotare il Web, in quanto sistema complesso, di questo genere di facoltà 'intelligenti' è lo scopo più ambizioso del progetto Web Semantico (che, per inciso, è ancora un'idea di Tim Berners-Lee16). Per raggiungere tale scopo sono necessarie numerosissime innovazioni, sia dal punto di vista tecnico, con la convergenza delle tecnologie sviluppate nell'ambito dell'Intelligenza Artificiale con quelle nate per sostenere l'architettura del Web, sia da quello dei comportamenti sociali degli utenti, poiché il progetto richiederà il contributo diffuso dell'intera comunità della rete. In particolare, il progetto Web Semantico richiede che l'informazione sia inserita in rete non più in maniera 'grezza', ma accompagnata da metainformazioni che aiutino a classificarla dal punto di vista semantico, in maniera accurata e consistente. Un obiettivo certo desiderabile ma tutt'altro che facile da raggiungere, giacché implica un cambiamento radicale nel modo in cui i soggetti fornitori dell'informazione producono, organizzano e gestiscono l'informazione da essi prodotta. Nei prossimi anni vedremo se questa sfida avrà o meno successo. Due concetti importanti: multimedia e ipertestoI primi argomenti che è necessario affrontare in una trattazione sull'architettura del World Wide Web sono i concetti di ipertesto e di multimedia. Il Web, infatti, può essere definito come un ipertesto multimediale distribuito: è dunque chiaro che tali concetti delineano la cornice generale nella quale esso e tutte le tecnologie sottostanti si inseriscono. Ormai da diversi anni i termini ipertesto e multimedia sono usciti dagli ambiti ristretti degli specialisti, per ricorrere con frequenza crescente nei contesti più disparati, dalla pubblicistica informatica fino alle pagine culturali dei quotidiani. Purtroppo questa 'inflazione' terminologica ha ingenerato una certa confusione, anche perché in fatto di tecnologie la pubblicistica mostra spesso una assoluta mancanza di rigore, quando non ci si trova di fronte a vera e propria incompetenza. Questo paragrafo intende fornire, in poche righe, una breve introduzione a questi concetti: alcuni minimi strumenti terminologici e teorici necessari per comprendere il funzionamento di World Wide Web. In primo luogo è bene distinguere il concetto di multimedialità da quello di ipertesto. I due concetti sono spesso affiancati e talvolta sovrapposti, ma mentre il primo si riferisce agli strumenti e ai codici della comunicazione, il secondo riguarda la sfera più complessa della organizzazione dell'informazione. Con multimedialità, dunque, ci si riferisce alla possibilità di utilizzare contemporaneamente, in uno stesso messaggio comunicativo, più media e/o più linguaggi17. Da questo punto di vista, possiamo dire che una certa dose di multimedialità è intrinseca in tutte le forme di comunicazione che l'uomo ha sviluppato e utilizzato, a partire dalla complessa interazione tra parola e gesto, fino alla invenzione della scrittura, dove il linguaggio verbale si fonde con l'iconicità del linguaggio scritto (si pensi anche - ma non unicamente - alle scritture ideografiche), e a tecnologie comunicative più recenti come il cinema o la televisione. Nondimeno l'informatica - e la connessa riduzione di linguaggi diversi alla 'base comune' rappresentata dalle catene di 0 e 1 del mondo digitale - ha notevolmente ampliato gli spazi 'storici' della multimedialità. Infatti attraverso la codifica digitale si è oggi in grado di immagazzinare in un unico oggetto informativo, che chiameremo documento, pressoché tutti i linguaggi comunicativi usati dalla nostra specie: testo, immagine, suono, parola, video. I documenti multimediali sono oggetti informativi complessi e di grande impatto. Ma oltre che nella possibilità di integrare in un singolo oggetto diversi codici, il nuovo orizzonte aperto dalla comunicazione su supporto digitale risiede nella possibilità di dare al messaggio una organizzazione molto diversa da quella cui siamo abituati da ormai molti secoli. È in questo senso che la multimedialità informatica si intreccia profondamente con gli ipertesti, e con l'interattività. Vediamo dunque cosa si intende con il concetto di ipertesto. La definizione di questo termine potrebbe richiedere un volume a parte (ed esistono realmente decine di volumi che ne discutono!). La prima formulazione moderna dell'idea di ipertesto si trova in un articolo del tecnologo americano Vannevar Bush, As We May Think, apparso nel 1945, dove viene descritta una complicata macchina immaginaria, il Memex (contrazione di Memory extension). Si trattava di una sorta di scrivania meccanizzata, dotata di schermi per visualizzare e manipolare documenti microfilmati, e di complicati meccanismi con cui sarebbe stato possibile costruire legami e collegamenti tra unità informative diverse. Secondo Bush un dispositivo come questo avrebbe aumentato la produttività intellettuale perché il suo funzionamento imitava il meccanismo del pensiero, basato su catene di associazioni mentali. La sintesi tra le suggestioni di Bush e le tecnologie informatiche è stata opera di Ted Nelson, che ha anche coniato il termine 'ipertesto', agli inizi degli anni '60. Nel suo scritto più famoso e importante, Literary Machines - un vero e proprio manifesto dell'ipertestualità - questo geniale e anticonformista guru dell'informatica statunitense descrive un potente sistema ipertestuale, battezzato Xanadu18. Nella utopica visione di Nelson, Xanadu era la base di un universo informativo globale e orizzontale - da lui definito docuverse (docuverso) - costituito da una sconfinata rete ipertestuale distribuita su una rete mondiale di computer. Il progetto Xanadu non è mai stato realizzato concretamente, nonostante i molti tentativi cui Nelson ha dato vita. Ma le sue idee sono confluite molti anni più tardi nella concezione di World Wide Web. In questa sede non possiamo affrontare compiutamente tutti gli aspetti teorici e pratici connessi con questo tema, ma solo fornire alcuni elementi esplicativi. In primo luogo, per comprendere cosa sia un ipertesto è opportuno distinguere tra aspetto logico-astratto e aspetto pratico-implementativo. Dal punto di vista logico un ipertesto è un sistema di organizzazione delle informazioni (testuali, ma non solo) in una struttura non sequenziale, bensì reticolare. Nella cultura occidentale, a partire dalla invenzione della scrittura alfabetica, e in particolare da quella della stampa, l'organizzazione dell'informazione in un messaggio, e la corrispondente fruizione della stessa, è essenzialmente basata su un modello lineare sequenziale, su cui si può sovrapporre al massimo una strutturazione gerarchica. Per capire meglio cosa intendiamo basta pensare a un libro, il tipo di documento per eccellenza della modernità: un libro è una sequenza lineare di testo, eventualmente organizzato come una sequenza di capitoli, che a loro volta possono essere organizzati in sequenze di paragrafi, e così via. La fruizione del testo avviene pertanto in modo sequenziale, dalla prima all'ultima pagina. Certo sono possibili deviazioni (letture 'a salti', rimandi in nota), ma si tratta di operazioni 'innestate' in una struttura nella quale prevale la linearità. Il 'lettore implicito' della maggior parte dei testi finora prodotti dalla cultra occidentale - ovvero il lettore ideale per il quale quei testi sono stati scritti - inizia a leggere il testo dall'inizio, e prosegue linearmente fino alla fine. Un ipertesto invece si basa su un'organizzazione reticolare dell'informazione, ed è costituito da un insieme di unità informative (i nodi) e da un insieme di collegamenti (detti nel gergo tecnico link) che da un nodo permettono di passare a uno o più altri nodi. Se le informazioni che sono collegate tra loro nella rete non sono solo documenti testuali, ma in generale informazioni veicolate da media differenti (testi, immagini, suoni, video), l'ipertesto diventa multimediale, e viene definito ipermedia. Una idea intuitiva di cosa sia un ipertesto multimediale può essere ricavata dalla figura 116.
I documenti di testo, l'immagine, il file audio e il video sono i nodi dell'ipertesto, mentre le frecce rappresentano i collegamenti (link) tra i vari nodi: il documento di testo al centro, ad esempio, contiene cinque link, grazie ai quali è possibile saltare ad altri due documenti, alla sequenza video, alla immagine e, infine, al file audio. Il lettore (o forse è meglio dire l'iper-lettore), dunque, non è vincolato dalla sequenza lineare dei contenuti di un certo documento, ma può muoversi da una unità testuale a un'altra (o a un blocco di informazioni veicolato da un altro medium) costruendosi ogni volta un proprio percorso di lettura. Naturalmente i vari collegamenti devono essere collocati in punti in cui il riferimento ad altre informazioni sia semanticamente rilevante: per un approfondimento, per riferimento tematico, per contiguità analogica. In caso contrario si rischia di rendere inconsistente l'intera base informativa, o di far smarrire il lettore in peregrinazioni prive di senso. Dal punto di vista della implementazione concreta, un ipertesto digitale si presenta come un documento elettronico in cui alcune porzioni di testo o immagini presenti sullo schermo, evidenziate attraverso artifici grafici (icone, colore, tipo e stile del carattere), rappresentano i diversi collegamenti disponibili nella pagina. Questi funzionano come dei pulsanti che attivano il collegamento e consentono di passare, sullo schermo, al documento di destinazione. Il pulsante viene 'premuto' attraverso un dispositivo di input, generalmente il mouse, una combinazioni di tasti, o un tocco su uno schermo touch-screen. In un certo senso, il concetto di ipertesto non rappresenta una novità assoluta rispetto alla nostra prassi di fruizione di informazioni testuali. La struttura ipertestuale infatti rappresenta una esaltazione 'pluridimensionale' del meccanismo testo/nota/riferimento bibliografico/glossa, che già conosciamo sia nei manoscritti sia nelle pubblicazioni a stampa. In fondo, il modo di lavorare di uno scrittore nella fase di preparazione del suo materiale è quasi sempre ipertestuale, così come l'intertestualità soggiacente alla storia della letteratura e allo sviluppo dei generi (dove 'letteratura' e 'generi' vanno presi nel loro senso ampio di produzione testuale, non esclusivamente dotata di valore estetico) costituisce una sorta di ipertesto virtuale che si genera nella mente di autore e lettore. Tuttavia, le tecnologie informatiche consentono per la prima volta di portare almeno in parte in superficie questo universo pre-testuale e post-testuale, per farlo diventare una vera e propria forma del discorso e dell'informazione. L'altro aspetto che fa dell'ipertesto elettronico uno strumento comunicativo dalle enormi potenzialità è la interattività che esso consente al fruitore, non più relegato nella posizione di destinatario più o meno passivo del messaggio, ma capace di guidare e indirizzare consapevolmente il suo atto di lettura. L'incontro tra ipertesto, multimedialità e interattività rappresenta dunque la nuova frontiera delle tecnologie comunicative. Il problema della comprensione teorica e del pieno sfruttamento delle enormi potenzialità di tali strumenti, specialmente in campo didattico, pedagogico e divulgativo (così come in quello dell'intrattenimento e del gioco), è naturalmente ancora in gran parte aperto: si tratta di un settore nel quale vi sono state negli ultimi anni - ed è legittimo aspettarsi negli anni a venire - innovazioni di notevole portata. L'architettura e i protocolli di World Wide WebIl concetto di ipertesto descrive la natura logica di World Wide Web. Si tratta infatti di un insieme di documenti multimediali interconnessi a rete mediante molteplici collegamenti ipertestuali e archiviati sui vari host che costituiscono Internet. Ciascun documento considerato dal punto di vista dell'utente viene definito pagina Web, ed è costituito da testo, immagini fisse e in movimento, in definitiva ogni tipo di oggetto digitale. Di norma le pagine Web sono riunite in collezioni riconducibili a una medesima responsabilità autoriale o editoriale, e talvolta, ma non necessariamente, caratterizzate da coerenza semantica, strutturale o grafica. Tali collezioni sono definiti siti Web. Se consideriamo il Web come un sistema di editoria on-line, i siti possono essere assimilati a singole pubblicazioni. Attivando uno dei collegamenti contenuti nella pagina correntemente visualizzata, essa viene sostituita dalla pagina di destinazione, che può trovarsi su un qualsiasi computer della rete. In questo senso utilizzare uno strumento come il Web permette di effettuare una sorta di navigazione in uno spazio informativo astratto, comunemente definito cyberspazio. Ma quali tecnologie soggiacciono a tale spazio astratto? In linea generale l'architettura informatica di World Wide Web non differisce in modo sostanziale da quella delle altre applicazioni Internet. Anche in questo caso, infatti, ci troviamo di fronte a un sistema basato su una interazione client-server, dove le funzioni elaborative sono distribuite in modo da ottimizzare l'efficienza complessiva. Il protocollo di comunicazione tra client e server Web si chiama HyperText Transfer Protocol (HTTP). Si tratta di un protocollo applicativo che a sua volta utilizza come base gli stack TCP/IP per inviare i dati attraverso la rete. La prima versione di HTTP è stata sviluppata da Tim Berners-Lee e ha continuato a far funzionare il Web per molti anni prima che venisse aggiornata alla versione 1.1, caratterizzata da una serie di migliorie sul piano dell'efficienza (HTTP 1.1 utilizza una sola connessione TCP per trasmettere dati e definisce delle regole per il funzionamento della cache sul lato client) e della sicurezza delle transazioni. A differenza di altre applicazioni Internet, tuttavia, il Web definisce anche dei formati o linguaggi specifici per i tipi di dati che possono essere inviati dal server al client. Tali formati e linguaggi specificano la codifica dei vari oggetti digitali che costituiscono un documento, e il modo di rappresentare i collegamenti ipertestuali che lo legano ad altri documenti. Tra essi ve ne è uno che assume un ruolo prioritario nel definire struttura, contenuto e aspetto di un documento/pagina Web: attualmente si tratta del linguaggio HyperText Markup Language (HTML). Un client Web costituisce lo strumento di interfaccia tra l'utente e il sistema Web; le funzioni principali che esso deve svolgere sono:
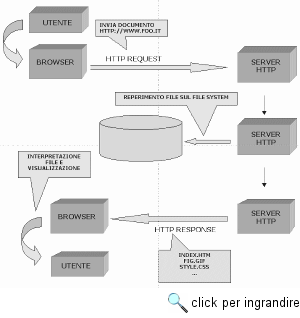
I client Web vengono comunemente chiamati browser, dall'inglese to browse, scorrere, sfogliare, poiché essi permettono appunto di scorrere le pagine visualizzate. Poiché tuttavia la fruizione di una pagina Web non è riducibile formalmente alla sola visualizzazione, nei documenti tecnici si preferisce la formula user agent, che cattura in modo più astratto il ruolo funzionale svolto dal client. Un server Web, o più precisamente server HTTP, per contro, si occupa della gestione, del reperimento e dell'invio dei documenti (ovvero dei vari oggetti digitali che li costituiscono) richiesti dai client. Nel momento in cui l'utente attiva un collegamento - agendo su un link - o specifica esplicitamente l'indirizzo di un documento, il client invia una richiesta HTTP (HTTP request) a un determinato server con l'indicazione del documento che deve ricevere. Questa richiesta viene interpretata dal server, che a sua volta invia gli oggetti che compongono il documento richiesto corredati da una speciale intestazione HTTP che ne specifica il tipo. Tale specificazione si basa sui codici di tipo definiti dalla codifica MIME (o MIME type), nata per la posta elettronica. Se necessario, il server prima di inviare i dati può effettuare delle procedure di autenticazione, in modo da limitare l'accesso a un documento a utenti autorizzati e in possesso di password.
In realtà per svolgere le sue mansioni un server HTTP può agire in due modi, a seconda che il documento richiesto dal client sia generato in modo statico o dinamico. Un documento Web statico è costituito da una serie di oggetti digitali memorizzati in file, che vengono prodotti una volta per tutte e messi in linea a disposizione degli utenti, fino a quando il gestore di sistema non decide di modificarli o di rimuoverli. Quando il server riceve una richiesta che si riferisce a un documento statico non deve far altro che individuare sulle proprie memorie di massa i vari file di cui si compone e inviarne delle copie al client. Un documento Web generato dinamicamente, invece, è un documento i cui componenti vengono elaborati e composti sul lato server solo nel momento in cui arriva una richiesta esplicita. Questo tipo di architettura Web, che si è evoluta notevolmente negli ultimi anni (forse ricorderete che ce ne siamo già occupati parlando di weblog), viene utilizzata nei casi in cui è necessario generare dei contenuti in maniera dinamica, in modo automatico o in risposta a una operazione interattiva effettuata dall'utente: ad esempio per aggiornare automaticamente i valori contenuti in una tabella numerica o per inviare, inseriti in un opportuno contesto, i risultati di una ricerca su un database. Naturalmente il server Web in quanto tale non è un grado di effettuare queste elaborazioni dinamiche. Per farlo si deve appoggiare a programmi esterni o a librerie di funzioni utilizzate in modo dinamico. Molteplici tecnologie sono state sviluppate nel corso degli anni a tale fine. La più 'rudimentale' si basa sulla cosiddetta Common Gateway Interface (CGI). Si tratta di un insieme di comandi e di variabili di memoria attraverso cui il server Web può comunicare con altre applicazioni e programmi autonomi. Tali programmi ricevono dal server un messaggio in cui viene richiesta una data elaborazione (ad esempio un sistema di gestione di database può ricevere la richiesta di effettuare una ricerca mediante alcune chiavi), la effettuano, e restituiscono l'output (nel nostro caso il risultato della ricerca) a un altro programma che lo codifica in un formato legale sul Web, il quale viene a sua volta restituito al server HTTP che infine provvede a inviarlo al client. L'architettura CGI insomma è un 'collante' a bassa integrazione tra applicazioni sostanzialmente autonome. Con lo sviluppo del Web, tuttavia, sono state predisposte soluzioni più evolute e soprattutto più efficienti per generare contenuti dinamici. Queste tecnologie si basano sul potenziamento della capacità di elaborazione autonome del server HTTP - mediante l'uso di linguaggi di programmazione e di scripting server-side come ASP e PHP - e/o sulla integrazione tra lo stesso server Web, server applicativi e database management system esterni. Da questa linea di sviluppo nasce il concetto di Web application service, su cui torneremo più avanti. Un'altra tipica funzione svolta dal server è la gestione di transazioni economiche, quali la registrazione di un acquisto fatto con carta di credito. Dal punto di vista tecnico questa operazione non differisce molto dalla normale consultazione o aggiornamento di un database. Ma ovviamente i problemi di affidabilità e di sicurezza in questo caso sono molto più rilevanti: per questo sono stati sviluppati dei server HTTP specializzati nella gestione di transazioni economiche sicure attraverso complesse tecnologie di cifratura di dati (anche di questo torneremo a parlare nel capitolo sulla sicurezza). Identificare e localizzare i documenti in reteWorld Wide Web è costituito da una collezione di documenti, ciascuno dei quali è formato da uno o più oggetti digitali archiviati, sotto forma di file, sugli host di Internet. Affinché tali oggetti siano individuabili e accessibili da un determinato user agent (di norma un browser, ma anche il modulo spider di un motore di ricerca), è necessario un adeguato sistema di identificazione e localizzazione delle risorse on-line, esattamente come i file archiviati nelle memorie di massa di un singolo computer sono gestiti dal file system del sistema operativo. Di fatto tutti i protocolli in uso su Internet sono dotati di un qualche sistema interno per individuare e localizzare le risorse: in termini tecnici possiamo dire che ogni protocollo individua un insieme di oggetti che possono essere raggiunti associando loro un nome o un indirizzo. I nomi o indirizzi usati da un protocollo sono validi solo nell'ambito delle risorse accessibili mediante il protocollo stesso: tale ambito viene definito spazio dei nomi. Ogni protocollo dunque ha uno schema di denominazione che individua uno spazio dei nomi. Se però, come avviene con il Web, un sistema può o deve accedere a risorse collocate in spazi diversi, si rende necessaria la creazione di uno spazio universale dei nomi e degli indirizzi, che permetta di identificare ogni risorsa astraendo dai requisiti tecnici di ogni singolo protocollo. Tanto più che tale spazio astratto dei nomi rimarrebbe valido anche nel caso in cui fosse modificato il modo in cui un protocollo accede alle risorse: basterebbe una modifica all'algoritmo che dal nome o indirizzo universale porta alla stringa di localizzazione effettiva del protocollo. Lo stesso potrebbe dirsi per la creazione di nuovi protocolli. Un membro dell'insieme di nomi o indirizzi in tale spazio universale viene definito Universal Resource Identifier (URI). Ogni URI è suddivisa in due parti principali: uno specificatore di schema seguito da una stringa di identificazione dell'oggetto (path), la cui forma è determinata dallo schema (a sua volta funzione del protocollo cui è associato). Le due parti sono separate dal simbolo ':' (due punti): schema : path Se lo schema individua uno spazio dei nomi o degli indirizzi organizzato gerarchicamente, esso può essere rappresentato da una serie di sottostringhe separate dal simbolo '/' (barra in avanti) il cui verso va da destra a sinistra. Alcuni schemi permettono di individuare anche parti di un oggetto. In tale caso la stringa che identifica tale parte (identificatore di frammento) viene posta alla estremità destra del path preceduta dal simbolo '#' (cancelletto). Al momento l'unica forma di URI che viene effettivamente utilizzata è quella denominata Uniform Resource Locator (URL). Una URL è una forma di URI che esprime l'indirizzo (ovvero la collocazione reale) di un oggetto accessibile mediante uno dei protocolli attualmente in uso su Internet. Per risolvere una serie di problemi legati alla natura delle URL, da alcuni anni è in fase di sviluppo una nuova forma di URI, denominata Universal Resource Name (URN). Una URN, a differenza di una URL, esprime il nome di un oggetto in un dato spazio dei nomi indipendentemente dalla sua collocazione fisica. Uniform Resource Locator (URL)Le Uniform Resource Locator (URL), come detto, sono un sottoinsieme del più generale insieme delle URI. Esse codificano formalmente l'indirizzo di ogni risorsa disponibile su Web in modo astratto rispetto agli effettivi algoritmi di risoluzione implementati in ciascun protocollo. Allo stato attuale le URL sono l'unico sistema di identificazione e localizzazione delle risorse di rete effettivamente utilizzato, sebbene ciò determini una serie di problemi sui quali ci soffermeremo nel prossimo paragrafo. La sintassi di una URL, basata naturalmente su quella delle URI, si articola in tre parti:
Di conseguenza una URL ha la seguente forma generale (le parti tra parentesi quadre sono opzionali): SCHEMA://[username:password@]identificatore.host[:numeroporta]/[path] Un esempio di URL per una risorsa Web, è il seguente: http://www.liberliber.it/index.htm Naturalmente ogni singolo schema di indirizzamento può presentare delle varianti a questa forma generale. Gli schemi registrati e attualmente implementati (corrispondenti ai vari protocolli in uso su Internet) sono i seguenti:
Per gli schemi http, ftp e file, la sezione del path di una URL ha una struttura gerarchica che corrisponde alla collocazione del file dell'oggetto referenziato nella porzione di file system visibile dal server. A ogni server infatti viene assegnato uno spazio sulla memoria di massa che inizia da una data directory (la root del server) e comprende tutte le sue sub-directory. La sezione del path di una URL seleziona la root del server mediante il primo simbolo '/' dopo l'indirizzo dell'host, e le successive sub-directory con i relativi nomi separati da simboli '/'. Ad esempio, se la root di un server HTTP sul file system ha il path '/user/local/httpd/htdocs', la URL 'http://www.foo.it/personal/rossi/index.html' si riferirà al file '/user/local/httpd/htdocs/personal/rossi/index.html'. Con lo schema http è possibile usare delle URL relative, che vengono risolte estraendo le informazioni mancanti dalla URL del documento corrente. Gli schemi 'mailto' e 'news' hanno una sintassi parzialmente diversa da quella generale che abbiamo visto sopra. Per la precisione una URL che si riferisce a un indirizzo di posta elettronica si presenta in questa forma: mailto:identificatore_utente@identificatore.host Ad esempio: mailto:rossi@uniroma.it Lo schema per i messaggi su server NNTP ha invece la seguente sintassi: news:nome_newsgroup[:numero_messaggio] Ad esempio: news:comp.text.xml:1223334 Si noti che a differenza degli altri schemi che indicano una collocazione assoluta della risorsa, valida ovunque, lo schema news è indipendente dalla collocazione, poiché seleziona un messaggio che ogni client dovrà reperire dal suo server locale. La sintassi delle URL può essere utilizzata sia nelle istruzioni ipertestuali dei file HTML, sia con i comandi che i singoli client, ciascuno a suo modo, mettono a disposizione per raggiungere un particolare server o documento. È bene pertanto che anche il normale utente della rete Internet impari a servirsene correttamente. Uniform Resource Name (URN)Une delle esperienze più comuni tra gli utilizzatori abituali di World Wide Web è la comparsa del famigerato 'errore 404', e cioè di un messaggio che annuncia l'impossibilità di accedere a una data risorsa quando si attiva un link ipertestuale o si digita una URL nella barra degli indirizzi del browser. Che cosa è avvenuto? Semplicemente che il file corrispondente non si trova più nella posizione indicata dal suo indirizzo. Che fine ha fatto? Può essere stato spostato, cancellato, rinominato. Il fatto è che i riferimenti in possesso dell'utente non gli permettono più di accedere al suo contenuto. Un'esperienza simmetrica è la scoperta che il contenuto di un certo documento, di cui magari si era inserita la URL nell'elenco dei bookmark, è cambiato. Anche in questo caso la causa del problema è molto semplice: al file 'xyz.html', pur conservando lo stesso indirizzo, è stato cambiato il contenuto. Alla radice di queste spiacevoli esperienze c'è uno dei limiti più importanti della attuale architettura di World Wide Web: il sistema di assegnazione dei nomi alle risorse informative sulla rete, e il modo in cui queste vengono localizzate. Come sappiamo, attualmente queste due funzioni sono svolte entrambe dalla URL di un documento. Il problema fondamentale è che la URL fornisce un ottimo sistema di indirizzamento (ovvero indica con molta efficienza la posizione di un oggetto sulla rete), ma un pessimo schema di assegnazione di nomi. La fusione delle funzioni di indirizzamento e di identificazione delle risorse in una unica tecnologia si rivela un sistema inadeguato in molti altri settori. A titolo di esempio: introduce grossi problemi nello sviluppo di applicazioni di information retrieval sulla rete; rende molto difficile la citazione, il riferimento e la catalogazione bibliografica dei documenti presenti in rete; non permette lo sviluppo di sistemi di versioning, ovvero sistemi che tengano traccia dell'evoluzione dinamica di un documento, conservandone le versioni successive; complica la gestione del mirroring, ovvero la creazione e l'allineamento di molteplici esemplari di un medesimo documento. Lo sviluppo di un efficiente sistema di distribuzione dell'informazione su rete geografica richiede dunque un potente e affidabile sistema di identificazione delle risorse informative. Per rispondere a questa esigenza, vari enti e organizzazioni che si occupano dello sviluppo degli standard su Internet hanno proposto la creazione di un nuovo tipo di URI, denominato Uniform Resource Name (URN). In realtà con questa sigla vengono indicate una serie di tecnologie, ancora in fase sperimentale, nate in ambiti diversi e caratterizzate da diversi approcci e finalità immediate. Nell'ottobre del 1995, in una conferenza tenuta alla University of Tennessee, i vari gruppi interessati hanno definito un sistema di specifiche unitarie. La convergenza prevede la compatibilità tra le varie implementazioni, pur garantendo la coesistenza di ognuna di esse. Dal 1996 la IETF, che si occupa della definizione degli standard per Internet, ha creato un gruppo di lavoro sugli URN. Chi è interessato ad approfondire gli aspetti tecnici e gli sviluppi in corso può consultare le pagine Web di questa commissione, il cui indirizzo è http://www.ietf.org/ html.charters/ urn-charter.html. In questa sede ci limiteremo a esporre le caratteristiche generali dell'architettura URN. Un URN è un identificatore che può essere associato a ogni risorsa disponibile su Internet, e che dovrebbe essere utilizzato in tutti i contesti che attualmente fanno uso delle URL. In generale, esso gode delle seguenti caratteristiche:
Per risorsa si intende il 'contenuto' di un documento (testo, immagine, animazione, software, ecc.), o una sua particolare manifestazione: ad esempio, ogni versione di un documento in un dato formato può avere un URN. Ciascuna risorsa individuata da un URN può essere disponibile in molteplici copie, distribuite su diversi luoghi della rete: conseguentemente, a ogni URN possono corrispondere molteplici URL. Il processo di determinazione delle URL di una risorsa a partire dalla sua URN viene definito 'risoluzione'. I nomi vengono assegnati da una serie di autorità indipendenti, dette naming authority, che garantiscono la loro unicità e permanenza. A ogni naming authority corrisponde almeno un Name Resolution Service, ovvero un sistema software che effettua la risoluzione del nome19. I problemi che si cerca di risolvere attraverso l'introduzione degli URN sono molto rilevanti, anche se, allo stato attuale, non esiste nessuna implementazione pubblica dell'architettura URN. I processi di standardizzazione, come al solito, sono molto lenti, specialmente in un ambiente decentralizzato come Internet. Il consenso necessario alla introduzione di una tecnologia completamente nuova richiede il concorso di molti soggetti, e non di rado impone agli attori commerciali notevoli investimenti nella progettazione o modifica dei prodotti software. L'introduzione delle URN è, comunque, tra gli obiettivi nell'agenda del progetto Internet II, che coinvolge alcune grandi università statunitensi nella progettazione della rete del prossimo futuro. Nel frattempo, è stato sviluppato un sistema che offre un'ottima approssimazione delle funzionalità di identificazione univoca dei documenti sulla rete. Si tratta delle Persistent URLs (PURLs), non casualmente messe a punto nell'ambito bibliotecario. Il sistema infatti nasce come progetto di ricerca sponsorizzato dalla OCLC, consorzio internazionale di biblioteche, di cui abbiamo parlato nel capitolo 'Biblioteche in rete'. Il sistema PURLs, come indica il nome, si basa sull'attuale meccanismo di indirizzamento dei documenti su Web e dunque non richiede alcuna modifica negli attuali browser. In effetti una PURL è, sia dal punto di vista funzionale sia da quello sintattico, una normale URL, e può essere utilizzata negli stessi contesti (all'interno dei file HTML, nelle finestre dei browser, ecc.). Questa ad esempio, rimanda a un documento introduttivo sul tema: http://purl.oclc.org/ OCLC/ PURL/ SUMMARY/. Invece che puntare direttamente verso la risorsa indirizzata, una PURL punta a uno speciale server che ospita un sistema di risoluzione (PURL resolution service): nell'esempio il servizio ha l'indirizzo 'purl.oclc.org'. Quest'ultimo, in base al nome della risorsa - nell'esempio /OCLC/PURL/SUMMARY/ - traduce la PURL in una vera e propria URL, e reindirizza il client verso questo indirizzo. Il meccanismo si basa su una normale transazione HTTP, detta redirezione. L'effettiva localizzazione della risorsa viene determinata dinamicamente dal PURL Service. Se un documento registrato presso un sistema di risoluzione PURL viene spostato (o se cambia il nome del file corrispondente), è sufficiente cambiare l'associazione PURL-URL nel database del servizio. La PURL rimane immutata e dunque tutti i riferimenti e i link da qualsiasi parte della rete verso quel documento continuano a funzionare perfettamente. L'aggiornamento delle relazioni deve essere effettuato esplicitamente dai responsabili della manutenzione del PURL Service. È comunque possibile eseguire questa operazione anche da computer remoti, e assegnare permessi di manutenzione per particolari gerarchie di nomi. Il primo PURL Resolution Service è stato attivato dalla OCLC nel gennaio del 1996, e si è dimostrato molto efficiente. Chi desidera vederlo in funzione può visitare l'indirizzo http://purl.oclc.org/. Naturalmente l'efficacia effettiva di questa tecnologia richiede la disseminazione attraverso la rete del maggior numero possibile di PURL server. Per facilitarne la diffusione, l'OCLC ha deciso di distribuire, gratuitamente il relativo software, che è disponibile sul sito Web indicato sopra. Molte istituzioni, specialmente nell'ambio bibliotecario e accademico, hanno dimostrato grande interesse, e hanno iniziato a sviluppare altri servizi di risoluzione PURL. Il sistema PURL costituisce un importante passo intermedio verso l'architettura URN. Inoltre, è ormai chiaro che la sintassi PURL sarà facilmente traducibile in forma di URN, trasformandola in uno schema di indirizzamento. Dunque coloro che oggi hanno adottato la tecnologia sviluppata dall'OCLC saranno in grado di migrare verso la tecnologia URN senza problemi. Nel frattempo le PURL, appoggiandosi sull'attuale sistema di indirizzamento utilizzato su Internet, hanno il chiaro vantaggio di essere già disponibili, di funzionare perfettamente e risolvere la sindrome da 'risorsa non disponibile'. I linguaggi del WebCome abbiamo anticipato, a differenza di altre applicazioni Internet, World Wide Web, oltre ai protocolli applicativi, definisce anche dei formati specifici per codificare i documenti che vi vengono immessi e distribuiti. I documenti che costituiscono la rete ipertestuale del Web sono principalmente documenti testuali, ai quali possono essere associati oggetti grafici (fissi o animati) e in taluni casi moduli software. In generale, comunque, struttura, contenuti e aspetto di una pagina Web visualizzata da un dato user agent sono definiti interamente nel documento testuale che ne costituisce l'oggetto principale. Tale definizione attualmente si basa su uno speciale linguaggio di rappresentazione dei documenti in formato elettronico, appartenente alla classe dei markup language (linguaggi di marcatura), denominato HyperText Markup Language (HTML). La formalizzazione di HTML, effettuata da uno dei gruppi di lavoro del W3C, è oggi completamente stabilizzata e tutti i browser disponibili sono in grado di interpretarne la sintassi e di rappresentare opportunamente i documenti in base ad essa codificati. Tuttavia, per ovviare ai numerosi limiti di HTML, lo stesso W3C ha sviluppato un (meta)linguaggio più potente e versatile per la creazione di documenti da distribuire su Web, denominato Extensible Markup Language (XML). Accanto a questo nuovo linguaggio sono stati formalizzati o sono in via di formalizzazione una serie di altri linguaggi che complessivamente trasformeranno l'intera architettura del Web, aumentandone capacità e versatilità. Nei prossimi paragrafi cercheremo di fornire ai lettori alcune nozioni di base sui principi e sulla natura di tutti questi linguaggi del Web. La rappresentazione elettronica dei documenti: i linguaggi di markupL'informatica mette a disposizioni diverse classi di formalismi per rappresentare dei documenti testuali su supporto elettronico. I più elementari sono i sistemi di codifica dei caratteri. Essi rappresentano il 'grado zero' della rappresentazione di un testo su supporto digitale, e sono alla base di tutti i sistemi più sofisticati: in linea generale ogni documento digitale è costituito da un flusso di caratteri (o stringa). Il carattere è l'unità atomica per la rappresentazione, l'organizzazione e il controllo di dati testuali sull'elaboratore. Come qualsiasi altro tipo di dati, anche i caratteri vengono rappresentati all'interno di un elaboratore mediante una codifica numerica binaria. Per la precisione, prima si stabilisce una associazione biunivoca tra gli elementi di una collezione di simboli (character repertoire) e un insieme di codici numerici (code set). L'insieme risultante viene denominato tecnicamente coded character set. Per ciascun coded character set, poi, si definisce una codifica dei caratteri (character encoding) basata su un algoritmo che mappa una o più sequenze di 8 bit (ottetto) al numero intero che rappresenta un dato carattere in un coded character set. Come alcuni lettori sapranno, esistono diversi coded character set - alcuni dei quali sono stati definiti da enti di standardizzazione nazionali e internazionali (ISO e ANSI in primo luogo) - che si differenziano per il numero di cifre binarie che utilizzano, e dunque per il numero di caratteri che possono codificare. Tra questi uno dei primi, e per lungo tempo il più diffuso, è stato il cosiddetto codice ASCII (American Standard Code for Information Interchange), la cui versione internazionale si chiama ISO 646 IRV. Esso utilizza solo 7 bit e di conseguenza contiene 128 caratteri, tra cui i simboli alfabetici dall'alfabeto anglosassone e alcuni simboli di punteggiatura. La diffusione dei computer ha naturalmente determinato l'esigenza di rappresentare i caratteri di altri alfabeti. Sono stati così sviluppati molteplici code set che utilizzano un intero ottetto (e dunque sono dotati di 256 posizioni) e che hanno di volta in volta accolto i simboli dei vari alfabeti latini. Tra di essi ricordiamo la famiglia ISO 8859, nel cui ambito particolarmente diffuso è il code set ISO 8859-1, meglio conosciuto come ISO Latin 1. Esso contiene i caratteri principali delle lingue occidentali con alfabeti latini, ed è usato da molte applicazioni su Internet e da molti sistemi operativi. Negli anni '90 sono state avviate due iniziative parallele per sistemare in modo definitivo (si spera) il problema della rappresentazione dei caratteri: la prima gestita dal consorzio Unicode (una organizzazione no-profit in cui convergono numerosi produttori di sistemi informatici), e la seconda dall'ISO. Da queste iniziative sono nati Unicode e ISO 10646/UCS, due coded character set che sono per fortuna perfettamente allineati (le differenze riguardano solo aspetti tecnici) e che, con qualche ragione, hanno la presunzione di definirsi 'universali'. In effetti si tratta di sistemi di codifica dei caratteri che possono adottare diverse character encoding basate su un numero variabile di bit: la codifica UTF-8 (la più diffusa attualmente), ad esempio, usa da uno a quattro ottetti a seconda dei sottoinsiemi di caratteri, mentre quella UTF-32/UCS4 (in un certo senso la codifica naturale per Unicode) usa sempre 32 bit. In realtà la questione di che cosa si intenda per carattere in Unicode e ISO 10646 e di come essi vengano effettivamente rappresentati nella memoria del computer è piuttosto complessa: per chi è interessato (e paziente) rimandiamo alla documentazione disponibile sul sito di Unicode (http://www.unicode.org/). Qui ci limiteremo a dire che il numero massimo teorico di caratteri che si possono codificare con questi standard è di oltre un milione e che, attualmente, sono stati codificati oltre 95 mila caratteri, tra cui si annoverano tutte le lingue occidentali, arabe e africane, e buona parte di quelle orientali. Anche se Unicode non viene ancora utilizzato da tutti i sistemi operativi e software esistenti (solo le versioni più recenti di Windows, ad esempio, lo implementano), è molto probabile che nel futuro prossimo la sua adozione diverrà quasi universale. La codifica dei caratteri, naturalmente, non esaurisce i problemi della rappresentazione elettronica di un documento. Se prendiamo un qualsiasi testo a stampa, già una semplice analisi ci permette di evidenziare una serie di fenomeni: la segmentazione del testo in macrounità, la presenza di titoli e sottotitoli, le enfasi, ecc. Per rappresentare su supporto informatico tutte le caratteristiche grafiche e strutturali di un documento, pertanto, vanno adottati formalismi più complessi. Tra questi vi sono i cosiddetti markup language, linguaggi di marcatura. L'espressione markup deriva dall'analogia tra questi linguaggi e le annotazioni inserite da autori, curatori editoriali e correttori nei manoscritti e nelle bozze di stampa di un testo al fine di indicare correzioni e trattamenti editoriali, chiamate in inglese mark-up. In modo simile, i linguaggi di marcatura sono costituiti da un insieme di istruzioni, dette tag (marcatori), che servono a descrivere la struttura, la composizione e l'impaginazione del documento. I marcatori sono sequenze di normali caratteri e vengono introdotti, secondo una determinata sintassi, all'interno del documento, accanto alla porzione di testo cui si riferiscono. Nel corso degli anni si sono delineate due diverse modalità di utilizzare e considerare il mark-up, che consentono di suddividere i linguaggi di markup in due tipologie:
I linguaggi del primo tipo (i cui testimoni più illustri sono lo Script, il TROFF, il TEX) sono costituiti da insiemi di istruzioni operative che indicano la struttura tipografica della pagina (il layout), le spaziature, l'interlineatura, i caratteri usati. Questi linguaggi sono detti procedurali in quanto istruiscono un dato programma circa le procedure di trattamento cui deve sottoporre la sequenza di caratteri nel momento dell'elaborazione (in gran parte dei casi la stampa o la visualizzazione su schermo). Nei linguaggi dichiarativi, invece, i marcatori sono utilizzati per assegnare ogni porzione di testo a una certa classe di caratteristiche testuali; essi permettono di descrivere la struttura astratta di un testo e le funzioni logiche dei suoi componenti. In questo modo il mark-up viene reso indipendente da ogni particolare applicazione ed elaborazione del documento. Il concetto di mark-up dichiarativo (insieme a numerosi altri concetti di estremo rilievo per potenziare l'elaborazione automatica di documenti testuali) è stato introdotto per la prima volta con lo sviluppo dello Standard Generalized Markup Language (SGML). Per la precisione, più che un linguaggio, lo SGML è un metalinguaggio. Esso prescrive precise regole sintattiche per definire un insieme di marcatori e le loro reciproche relazioni, ma non dice nulla per quanto riguarda la loro tipologia, quantità e nomenclatura. Questa astrazione costituisce il nucleo e la potenza dello SGML: in sostanza, SGML serve non già a marcare direttamente documenti, ma a costruire, rispettando standard comuni e rigorosi, specifici linguaggi di marcatura adatti per le varie esigenze particolari. Un linguaggio di marcatura che rispetti le specifiche SGML viene definito 'applicazione SGML' (SGML application). Ideato da Charles Goldfarb negli anni '70, SGML è divenuto nel 1986 lo standard ufficiale ISO per la creazione e l'interscambio di documenti elettronici, ed è stato adottato da numerose grandi istituzioni e aziende - ma anche dalla comunità dei ricercatori interessati alle applicazioni informatiche nel settore umanistico e letterario - per la gestione di grandi basi dati documentali20. Ma il successo maggiore di questa tecnologia è stato senza dubbio il fatto di avere influenzato in modo diverso la definizione dei due linguaggi di riferimento per la creazione di documenti Web: l'HyperText Markup Language (HTML) prima e l'Extensible Markup Language (XML) più recentemente. HyperText Markup Language (HTML)HyperText Markup Language (HTML) è il linguaggio attualmente più utilizzato per dare forma ai miliardi di documenti che popolano World Wide Web. Si tratta di un linguaggio di markup definito mediante la sintassi SGML e orientato alla descrizione di documenti testuali, con alcune estensioni per il trattamento di dati multimediali e soprattutto di collegamenti ipertestuali. Lo sviluppo di HTML è stato assai complesso e, soprattutto in una certa fase, piuttosto disordinato. Nella sua prima versione ufficiale, il linguaggio era estremamente semplice, e non prevedeva la possibilità di rappresentare fenomeni testuali ed editoriali complessi. Di conseguenza le sue specifiche hanno subito numerose revisioni che hanno dato origine a diverse versioni ufficiali, nonché a una serie di estensioni introdotte dai vari produttori di browser Web (in particolare, Microsoft e Netscape). Pur se in maniera un po' caotica, questi raffinamenti successivi, accogliendo le sollecitazioni provenienti da una comunità di utenti sempre più vasta e variegata, hanno progressivamente allargato la capacità rappresentazionale del linguaggio, introducendo - accanto a qualche marcatore di dubbia utilità - molti elementi utili a migliorare l'organizzazione strutturale e formale dei documenti. La costituzione del W3C ha permesso di standardizzare in modo definitivo il linguaggio, che è ormai finalmente stabilizzato. Nel dicembre del 1999, infatti, è stata rilasciata ufficialmente l'ultima versione, denominata HTML 4.01 (le specifiche formali sono disponibili all'indirizzo http://www.w3.org/TR/html4/21). HTML 4.01 ha accolto numerose innovazioni che erano precedentemente parte dei vari dialetti proprietari (ad esempio la tecnologia dei frame, che permette di suddividere la finestra del browser in sottofinestre contenenti file diversi, e le tabelle). Le caratteristiche più rilevanti di questa ultima standardizzazione sono state senza dubbio l'attenzione dedicata alla internazionalizzazione e l'integrazione del linguaggio HTML con un sistema di fogli di stile - tema su cui torneremo a breve - in modo da distinguere la struttura astratta del documento dalla sua presentazione formale. Inoltre HTML 4.01 è formalmente basato su Unicode ed è in grado di rappresentare sistemi di scrittura che hanno direzioni di scrittura diverse da quella occidentale (ad esempio in arabo e in ebraico la scrittura va da destra verso sinistra). Dunque, potenzialmente, esso permette la redazione e distribuzione di documenti redatti in ogni lingua e alfabeto e di documenti multilingua22. Queste caratteristiche si aggiungono agli elementi di base di HTML, che permettono di strutturare un documento e di inserire riferimenti ipertestuali e oggetti multimediali in una pagina Web. Ad esempio è possibile indicare i diversi livelli dei titoli di un documento, lo stile dei caratteri (corsivo, grassetto...), i capoversi, la presenza di liste (numerate o no). Volendo realizzare un documento ipermediale, avremo a disposizione anche marcatori specifici per la definizione dei link ipertestuali e per l'inserimento di immagini. Naturalmente le immagini non sono parte integrante del file HTML, che in quanto tale è un semplice file di testo. I file grafici vengono inviati come oggetti autonomi dal server, e inseriti in una pagina Web solo durante l'operazione di visualizzazione effettuata dal browser. I formati di immagini digitali standard su Web sono GIF, JPEG e PNG (altro standard W3C) . Si tratta di sistemi di codifica grafica in grado di comprimere notevolmente la dimensione del file, e pertanto particolarmente adatti a un uso su rete. Attraverso i marcatori HTML è possibile anche specificare alcune strutture interattive come moduli di immissione attraverso cui l'utente può inviare comandi e informazioni al server e attivare speciali procedure (ricerche su database, invio di posta elettronica e anche pagamenti attraverso carta di credito!); oppure disegnare tabelle. Un utente di Internet che desiderasse solo consultare e non produrre informazione in rete potrebbe fare a meno di approfondire sintassi e funzionamento di HTML. Attenzione, però: una delle caratteristiche fondamentali di Internet è proprio l'estrema facilità con la quale è possibile diventare protagonisti attivi dello scambio informativo. Se si vuole compiere questo salto decisivo, una conoscenza minima di HTML è preziosa. Non occorre avere timori reverenziali: HTML non è un linguaggio di programmazione, e imparare a usare le sue istruzioni di base non è affatto difficile, non più di quanto lo sia imparare a usare e a interpretare le principali sigle e abbreviazioni usate dai correttori di bozze. Per questi motivi nell'appendice 'Pubblicare informazioni su Internet' torneremo su questo linguaggio, approfondendo alcuni elementi della sua sintassi. Extensible Markup Language (XML)L'evoluzione di Internet procede incessantemente. La crescente richiesta di nuove potenzialità e applicazioni trasforma la rete in un continuo work in progress, un laboratorio dove si sperimentano tecnologie e soluzioni innovative. Se da una parte questo processo produce sviluppi disordinati, spesso determinati da singole aziende che cercano di trarre il massimo profitto dal fenomeno Internet, dall'altra le organizzazioni indipendenti che gestiscono l'evoluzione della rete svolgono una continua attività di ricerca e di definizione di nuovi standard. Tra questi, di gran lunga il più importante è senza dubbio Extensible Markup Language (XML), il nuovo linguaggio di markup definito dal W3 Consortium, che sta cambiando sostanzialmente l'architettura del Web, e non solo. Lo sviluppo di XML ha rappresentato la risposta a due esigenze in parte convergenti: in primo luogo il potenziamento delle funzionalità di gestione logica e presentazionale dei contenuti per la rete; in secondo luogo la possibilità di erogare servizi e applicazioni avanzate mediante il Web. Sebbene la formalizzazione di HTML abbia rappresentato una importante evoluzione, tuttavia essa non forniva una soluzione adeguata per ovviare ad alcuni importanti limiti dell'architettura originale del Web. La causa di tali limiti infatti risiede nel linguaggio HTML stesso. Possiamo suddividere i problemi determinati da HTML in due categorie:
La prima categoria è relativa al modo in cui vengono rappresentati i documenti. La rappresentazione e la codifica dei dati sono il fondamento di un sistema di gestione dell'informazione. Da questo punto vista HTML impone notevoli restrizioni: in primo luogo si tratta di un linguaggio di rappresentazione chiuso e non modificabile; l'autore di un documento può soltanto scegliere tra un insieme prefissato di elementi, anche se la struttura formale o quella semantica del suo documento richiederebbero di esplicitarne altri, o di qualificarli in modo diverso. In secondo luogo si tratta di un linguaggio scarsamente strutturato e con una sintassi troppo 'tollerante', che non consente di modellizzare esplicitamente oggetti informativi altamente organizzati come ad esempio una descrizione bibliografica, un record di database o un sonetto petrarchesco; conseguentemente non può essere usato come formato per la rappresentazione e l'interscambio di informazioni complesse (soprattutto se attori di tale scambio sono sistemi software). A questo si aggiunge la confusione determinata dalla presenza di istruzioni orientate più all'impaginazione grafica che alla descrizione strutturale dei documenti. Un'ulteriore limitazione riguarda la definizione dei link ipertestuali. Si potrebbe dire che questo linguaggio di codifica usurpa il suo nome. Infatti è in grado di esprimere un solo tipo di collegamento ipertestuale, unidirezionale, il quale richiede che sia l'origine sia la destinazione siano esplicitate nei rispettivi documenti. La ricerca teorica e applicata sui sistemi ipertestuali, invece, ha individuato sin dagli anni '70 una complessa casistica di collegamenti ipertestuali, che possono corrispondere a diverse relazioni semantiche. Dai limiti rappresentazionali discendono quelli operativi, che riguardano il modo in cui autori e lettori interagiscono con il sistema. In primo luogo il controllo sull'aspetto di un documento, come abbiamo visto, è assai limitato e rigido. Una pagina Web deve essere progettata per uno schermo dotato di determinate caratteristiche, con il rischio di avere risultati impredicibili su altri dispositivi di visualizzazione o nella stampa su carta. Inoltre HTML non consente di generare dinamicamente 'viste' differenziate di un medesimo documento in base alle esigenze del lettore. Tale capacità permetterebbe, ad esempio, di produrre diverse versioni linguistiche a partire da un unico documento multilingua; oppure, in un'applicazione di insegnamento a distanza, di mostrare o nascondere porzioni di un documento a seconda del livello di apprendimento dell'utente. E ancora, la scarsa consistenza strutturale impedisce la generazione automatica e dinamica di indici e sommari. E per lo stesso motivo si riduce notevolmente l'efficienza della ricerca di informazioni su Web. I motori di ricerca, infatti, sono sostanzialmente sistemi di ricerca full-text, che non tengono conto della struttura del documento e restituiscono riferimenti solo a documenti interi. Per superare questi limiti, alcuni anni fa fu proposto un vero e proprio salto di paradigma: la generalizzazione del supporto su Web allo Standard Generalized Markup Language (SGML). L'idea di base era piuttosto semplice: HTML è una particolare applicazione SGML, che risponde ad alcune esigenze; perché non modificare l'architettura del Web per consentire di usare anche altre applicazioni SGML? La possibilità di distribuire documenti elettronici in formato SGML avrebbe garantito ai fornitori di contenuti un notevole potere di controllo sulla qualità e sulla struttura delle informazioni pubblicate. Ogni editore elettronico avrebbe potuto utilizzare il linguaggio di codifica che maggiormente rispondeva alle sue esigenze, a cui associare poi uno o più fogli di stile al fine di controllare la presentazione dei documenti pubblicati. Questa soluzione, tuttavia, presentava non poche difficoltà:
Per superare questi ostacoli il W3C decise di sviluppare un sottoinsieme semplificato di SGML, pensato appositamente per la creazione di documenti su Web: Extensible Markup Language (XML)23. Il progetto XML ha avuto inizio alla fine del 1996, nell'ambito della SGML Activity del W3C, ma l'interesse che ha attirato sin dall'inizio (testimoniato da centinaia di articoli sulle maggiori riviste del settore) ha portato il W3C a creare un apposito gruppo di lavoro (XML Working Group), composto da oltre ottanta esperti mondiali, e una commissione (XML Editorial Review Board) deputata alla redazione delle specifiche. Dopo oltre un anno di lavoro, nel febbraio del 1998 le specifiche sono divenute una raccomandazione ufficiale, con il titolo Extensible Markup Language (XML) 1.0, di cui è stata rilasciata una revisione nel 2000. Attualmente è in fase di approvazione una nuova versione, Extensible Markup Language (XML) 1.1, la quale tuttavia introduce dei cambiamenti di aspetto esclusivamente tecnico. Come di consueto tutti i materiali relativi al progetto, documenti ufficiali, informazioni e aggiornamenti, sono pubblicati sul sito del consorzio all'indirizzo http://www.w3.org/XML/. XML, come anticipato, è un sottoinsieme di SGML semplificato e ottimizzato specificamente per applicazioni in ambiente Web. Rispetto al suo complesso progenitore è dotato di alcune particolarità tecniche che ne facilitano notevolmente l'implementazione, pur mantenendone gran parte dei vantaggi24. Anche XML, infatti, è un metalinguaggio che permette di specificare in modo formale il vocabolario e la grammatica di un particolare linguaggio di marcatura, definito applicazione XML. Questa, a sua volta, descrive la struttura logica di una classe o tipo di documenti - o, in generale, di oggetti informativi. Tale struttura astratta viene specificata individuando gli elementi che la costituiscono (ad esempio: capitolo, titolo, paragrafo, nota, citazione, ecc.) e le relazioni che tra questi intercorrono, relazioni che possono essere di natura gerarchica e ordinale. Infatti in XML un documento viene considerato come dotato di una (e una sola) struttura ad albero. La struttura di una classe di documenti XML può essere specificata esplicitamente mediante la definizione di una vera e propria grammatica formale, denominata Document Type Definition (DTD). Il formalismo per specificare la DTD è una eredità di SGML ed è completamente stabilizzato e ampiamente adottato. Tuttavia, per ovviare ad alcuni limiti espressivi di tale formalismo, sono stati proposti numerosi formalismi alternativi, denominati Schema Definition Language (dove il termine 'schema' eredita le funzioni di 'tipo di documento'). Al momento, tre delle numerose proposte sembrano, per diversi motivi, presentare elementi di interesse:
Senza approfondire i dettagli tecnici (piuttosto complessi), possiamo dire che primi due adottano una strategia concettualmente simile a quella della DTD, la definizione formale di grammatiche generali per i documenti, mentre il terzo si basa sull'individuazione di pattern (modelli) di (sotto)alberi in un documento XML, costruiti sulla base di determinati vincoli. Una volta definito, un determinato linguaggio di markup può essere utilizzato per creare singoli documenti, che ne dovranno rispettare i vincoli grammaticali, oltre a conformarsi alle norme generali di sintassi XML. Nel documento a ciascun elemento corrisponde una coppia di marcatori. La sintassi prevede che i marcatori siano racchiusi tra i simboli di minore e maggiore. Ogni elemento viene identificato da un marcatore iniziale e uno finale (costruito premettendo una barra al nome del marcatore iniziale), a meno che non sia un elemento vuoto (che non contenga cioè sotto-elementi o testo), nel qual caso è identificato solo da un marcatore iniziale che tuttavia presenta una barra prima del carattere '>'. Un testo codificato in XML dunque ha il seguente aspetto25: <text> <front> <titlepage> <docauthor>Corrado Alvaro</docauthor> <doctitle><titlepart type='main'>L'uomo nel labirinto</titlepart> <titlepart>in Il mare</titlepart> </doctitle> <docimprint> <pubplace>Milano</pubplace> <publisher>A. Mondadori</publisher> <docdate>1932</docdate> </docimprint> </titlepage> </front> <pb n='145'/> <body> <div1> <head>I</head> <p>La primavera arrivò improvvisamente; era l'anno dopo la guerra, e pareva che non dovesse piú tornare. [...]</p> La rispondenza tra documento e grammatica viene verificata in modo automatico da un parser. Un documento XML che ottempera a questa condizione viene detto valido. Tuttavia, a differenza di SGML, XML ammette anche l'esistenza di documenti privi di una DTD o di uno schema espliciti. Naturalmente tali documenti dovranno comunque rispettare una serie di norme sintattiche generali (che valgono cioè per ogni documento XML), dette vincoli di buona-formazione. Tra i vincoli sintattici di un documento ben-formato ricordiamo ad esempio: deve esistere un solo elemento radice; le coppie di marcatori debbono essere sempre annidate; è obbligatorio inserire i marcatori di chiusura negli elementi non vuoti; gli elementi vuoti hanno una sintassi leggermente modificata. Ciò riduce notevolmente la complessità di implementazione di un browser XML, e facilita l'apprendimento del linguaggio (le specifiche constano di venticinque pagine contro le cinquecento dello standard ISO). La semplificazione tuttavia non comporta incompatibilità: un documento XML valido è sempre un documento SGML valido (naturalmente non vale l'inverso). La trasformazione di un'applicazione o di un documento SGML in uno XML è (nella maggior parte dei casi) una procedura automatica. XML, oltre alla sua capacità espressiva, offre una serie di vantaggi dal punto di vista del trattamento informatico dei documenti. In primo luogo, poiché un documento XML è composto esclusivamente da una sequenza di caratteri in formato Unicode, esso è facilmente portabile su ogni tipo di computer e di sistema operativo. Inoltre un testo codificato in formato XML può essere utilizzato per scopi differenti (stampa su carta, presentazione multimediale, analisi tramite software specifici, elaborazione con database, creazione di corpus linguistici automatici), anche in tempi diversi, senza dovere pagare i costi di dolorose conversioni tra formati spesso incompatibili. E ancora, la natura fortemente strutturata di un documento XML si presta allo sviluppo di applicazioni complesse. Possiamo citare ad esempio l'aggiornamento di database; la creazione di strumenti di information retrieval contestuali; la produzione e la manutenzione di pubblicazioni articolate come documentazione tecnica, manualistica, corsi interattivi per l'insegnamento a distanza. L'interesse che la comunità degli sviluppatori di applicazioni e servizi Web ha dimostrato verso XML è stato decisamente superiore alle stesse aspettative del W3C, che si attendeva un periodo di transizione assai lungo verso la nuova architettura. In breve tempo le applicazioni XML si sono diffuse in ogni settore: dalla ricerca umanistica (dove una applicazione XML denominata Text Encoding Initiative è divenuta lo standard per la codifica e l'archiviazione dei testi su supporto digitale e per la creazione di biblioteche digitali26), a quella chimica (con il Chemical Markup Language, un linguaggio orientato alla descrizione di strutture molecolari), a quella matematica (con MathML, un linguaggio per la descrizione di formule e notazioni matematiche); dal commercio elettronico, alla distribuzione di applicazioni attraverso Internet; dall'editoria on-line (abbiamo già accennato ad esempio al formato OEBPS per la realizzazione di libri elettronici, basato anch'esso su XML) alle transazioni finanziarie. Ma soprattutto sin dall'inizio è stata resa disponibile una grande quantità di software (in gran parte open source) in grado di elaborare documenti XML: analizzatori sintattici (parsers), editor, browser, motori di ricerca. Gran parte dell'interesse è dovuto al fatto che XML, oltre che come formato di rappresentazione dei dati da presentare agli utenti, può essere utilizzato come formato per lo scambio di dati e messaggi tra applicazioni software che interagiscono in un ambiente distribuito e per la progettazione di soluzioni middleware, trovando applicazione nell'area del commercio elettronico, del lavoro collaborativo e nella creazione di Web services. Si collocano in questo settore gli standard - entrambi in formato XML - WSDL (Web Services Description Language) e SOAP (Simple Object Access Protocol) che permettono rispettivamente di descrivere le proprietà e i metodi forniti da applicazioni Web e di strutturare e formalizzare i dati e i messaggi (nel senso che questo termine assume nella programmazione a oggetti) che essi si possono scambiare. Tra le tante applicazioni XML, una menzione particolare merita XHTML (http://www.w3.org/TR/xhtml1/). Come alcuni lettori avranno immaginato, si tratta della ridefinizione in XML di HTML realizzata dal W3C. Rispetto alla versione standard, essa si distingue per l'aderenza ai vincoli di well-formedness di XML, ma al contempo può essere estesa senza problemi. Lo scopo di questa versione infatti è proprio quello di facilitare la transizione degli sviluppatori di risorse Web da HTML a XML con un passaggio intermedio rappresentato da XHTML. Gli standard correlati a XMLLa definizione del linguaggio XML non ha esaurito l'attività di innovazione dell'architettura Web. Infatti, intorno al progetto XML sono stati sviluppati o sono in via di sviluppo una serie di standard ulteriori che coprono altri aspetti, non meno importanti, del suo funzionamento. In particolare, ci riferiamo ai linguaggi per la creazione di fogli di stile CSS (Cascading Style Sheet), XSLT (Extensible Stylesheet Language-Transformation) e XSL-FO (Extensible Stylesheet Language-Formatting Object); ai linguaggi per la specificazione di collegamenti ipertestuali XLL (Extensible Linking Language) e XPointer; ai linguaggi per la definizione di schemi, cui abbiamo già accennato; al linguaggio SMIL (Synchronized Multimedia Integration Language) per la sincronizzazione di contenuti e presentazioni multimediali di flusso. Di un altro importante linguaggio XML, denominato RDF (Resource Description Framework), ci occuperemo invece nell'ultimo paragrafo dedicato al Web Semantico, poiché ne rappresenta le fondamenta. Nei prossimi paragrafi cercheremo di fornire alcune brevi informazioni su questi linguaggi, senza presumere di essere nemmeno lontanamente esaustivi. D'altra parte la complessità di questi temi, oltre a richiedere interi volumi per essere affrontata, esulerebbe del tutto dagli scopi di questo manuale. Questioni di stileSe XML fornisce una soluzione ai problemi di rappresentazione strutturale dei dati e dei documenti, i fogli di stile offrono una risposta all'esigenza di un maggiore e più raffinato controllo sulla presentazione degli stessi. Per lungo tempo, nell'architettura di World Wide Web, le regole di formattazione e la resa grafica di un documento sono state codificate nei browser. In questo modo, il controllo sull'aspetto della pagina da parte dell'autore è molto limitato, e si basa sull'uso di una serie di marcatori HTML ad hoc, introducendo inconsistenze strutturali nel documento. L'introduzione dei fogli di stile risolve entrambi i problemi poiché:
Il concetto di foglio di stile nasce nell'ambito delle tecnologie di word processing e desktop publishing. L'idea è quella di separare il contenuto testuale di un documento elettronico dalle istruzioni che ne governano l'impaginazione, le caratteristiche grafiche e la formattazione. Per fare questo è necessario suddividere il testo in blocchi etichettati e associare poi a ogni blocco uno specifico stile, che determina il modo in cui quella particolare porzione del testo viene impaginata sul video o stampata su carta. Ad esempio, a un titolo di capitolo può essere associato uno stile diverso da quello assegnato a un titolo di paragrafo o al corpo del testo (lo stile 'titolo di capitolo' potrebbe prevedere, poniamo, un carattere di maggiori dimensioni e in grassetto, la centratura, un salto di tre righe prima dell'inizio del blocco di testo successivo; a un blocco di testo citato potrebbe invece essere assegnato uno stile che prevede un corpo lievemente minore rispetto al testo normale, e dei margini maggiori a sinistra e a destra per poterlo 'centrare' nella pagina). Per chi usa un moderno programma di videoscrittura questo meccanismo, almeno a un livello superficiale, dovrebbe risultare familiare. I fogli di stile facilitano la formattazione dei documenti, permettono di uniformare lo stile di diversi testi dello stesso tipo, e semplificano la manutenzione degli archivi testuali. Infatti la modifica delle caratteristiche formali di uno o più documenti non richiede di effettuare un gran numero di modifiche locali. Se, ad esempio, una casa editrice decide di cambiare il corpo tipografico dei titoli di capitolo nelle sue pubblicazioni, sarà sufficiente modificare il foglio di stile per quella porzione di testo, e automaticamente tutti i testi erediteranno la nuova impostazione grafica. Il meccanismo dei fogli di stile si presta facilmente a essere applicato ai documenti codificati mediante linguaggi di markup derivati da SGML e XML. Questo tipo di linguaggi, infatti, si basa proprio sulla esplicitazione degli elementi strutturali di un testo attraverso i marcatori. È sufficiente dunque definire una notazione che permetta di associare a ogni marcatore uno stile. Naturalmente è poi necessario che il browser sia in grado di interpretare questa notazione, e di applicare le relative istruzioni di formattazione. Una notazione di questo tipo è un linguaggio per fogli di stile. Anche in questo settore il ruolo del W3C è stato determinante. Il Consortium, infatti, nell'ambito dei suoi gruppi di lavoro, ha elaborato entrambi i linguaggi attualmente utilizzati per definire fogli di stile sul Web. Il primo, sviluppato inizialmente per essere utilizzato con documenti HTML e successivamente esteso a XML, si chiama Cascading Style Sheet. Ideato originariamente da Håkon Lie alla fine del 1994, ha avuto una prima formalizzazione nel dicembre 1996. Nel maggio del 1998 è stata rilasciata come raccomandazione la seconda versione, che ha esteso notevolmente la prima versione in molte aree. In particolare ricordiamo: il trasferimento dinamico dei tipi di carattere sulla rete, in modo tale da garantire che l'aspetto di una pagina sia esattamente quello progettato anche se l'utente non ha i font specificati sul suo sistema locale; la specificazione di appositi stili orientati ai software di conversione vocale e ai display per disabili; l'estensione delle capacità di controllo sul layout e sulla numerazione automatica di liste, titoli, ecc., e la capacità di gestire diversi supporti di impaginazione per un medesimo documento (ad esempio la visualizzazione su schermo e la stampa su carta). Il testo definitivo delle specifiche, con il titolo Cascading Style Sheets, level 2 (CSS2), è disponibile sul sito Web del W3C, all'indirizzo http://www.w3.org/TR/REC-CSS2/. Attualmente è in corso il lavoro per la definizione di una terza versione. La caratteristica fondamentale di CSS, dalla quale deriva il nome, è la possibilità di sovrapporre stili in 'cascata'; in questo modo l'autore può definire una parte degli stili in un foglio globale che si applica a tutte le pagine di un sito, e un'altra parte in modo locale per ogni pagina, o persino per singoli elementi HTML all'interno della pagina. Le regole per risolvere definizioni conflittuali, esplicitate nelle specifiche, fanno sì che lo stile definito per ultimo prenda il sopravvento su tutte le definizioni precedenti. In teoria, se il browser lo consente, anche il lettore può definire i suoi stili. La sintassi CSS è molto semplice, almeno al livello base. Essa si basa sui selettori, che identificano gli elementi a cui attribuire un dato stile, e sulle proprietà, che contengono gli attributi di stile veri e propri. I selettori possono essere i nomi degli elementi, o una serie di valori di attributi, e sono seguiti dalle proprietà, racchiuse tra parentesi graffe e separate da punto e virgola. Ad esempio, per indicare che i titoli di primo livello in un documento HTML debbono usare un font 'Times' con dimensione di 16 punti tipografici in stile grassetto occorre scrivere quanto segue: H1{font-type: "Times"; font-size: 16pt; font-weight: bold} Per collegare un foglio di stile a un documento HTML sono previsti tre metodi: si può definire il foglio di stile in un file esterno, e collegarlo al file che contiene il documento HTML (mediante l'elemento <LINK>); si possono inserire le direttive CSS direttamente all'interno del file HTML, usando l'istruzione speciale <STYLE>; e infine si possono associare stili a ogni elemento usando l'attributo 'style'. Un meccanismo concettualmente simile, anche se basato su una sintassi diversa (per la precisione si utilizza una processing instruction) va utilizzato per associare un foglio di stile CSS a un documento XML27. Allo stato attuale il supporto ai fogli di stile CSS versione 1 è completo in tutti i browser di ultima generazione. Anche la seconda versione è quasi totalmente implementata, anche se non mancano le inconsistenze nel comportamento dei vari browser . La seconda tecnologia di fogli stile proposta dal W3C è stata sviluppata nell'ambito delle attività correlate alla definizione di XML. Si tratta dei linguaggi della famiglia Extensible Stylesheet Language: XSL-Transformation (XSLT), XPath e XSL - Formatting Object (XSL-FO). Del primo è stata rilasciata la prima versione nel novembre del 1999 (http://www.w3.org/TR/xslt/) ed è in corso di definizione la seconda (http://www.w3.org/TR/xslt20/); lo stesso vale per XPath, che è in realtà un componente condiviso da altre specifiche XML; il terzo è stato definito in versione 1 nell'ottobre del 2001 (http://www.w3.org/TR/xsl/). In realtà considerare XSLT un semplice linguaggio per specificare la presentazione di un documento XML è assai limitativo. In effetti XSLT è un vero e proprio linguaggio di programmazione dichiarativo (e Turing-completo28) che permette di trasformare un documento XML in un altro documento XML con una struttura diversa; per la precisione la trasformazione avviene da una data struttura astratta ad albero a un'altra, che poi viene 'serializzata' in un documento XML di output. Altro elemento qualificante di XSL è il fatto che la sua sintassi si basa su XML: un foglio di stile XSL è a sua volta un documento XML ben-formato. Il processo di trasformazione si basa sulla specificazione di una serie di regole modello (template) che determinano a quale nodo (o insieme di nodi) dell'albero iniziale vada applicata la trasformazione, e quale essa debba essere: ad esempio un nodo 'A' può essere trasformato in un sottoalbero con un nodo padre 'A' e due nodi figli 'B' e 'C'; i nodi 'Nome' presenti nel documento iniziale possono essere estratti, collocati in un nodo 'Indice' e ordinati, e così via. L'individuazione dei nodi oggetto del processo avviene mediante pattern formulati con la sintassi di XPath. Questo linguaggio, infatti, consente di costruire espressioni che selezionano uno o più nodi di un albero XML in base alla loro collocazione gerarchica, ordinale e/o al verificarsi di certe condizioni. Una della applicazioni più immediate di XSLT (che ne giustifica il nome), è la trasformazione di un documento XML codificato con un linguaggio XML qualsiasi in un documento HTML, in modo che sia visualizzabile immediatamente da un browser Web. Per effettuare la trasformazione, occorre utilizzare un programma in grado di interpretare ed eseguire le istruzioni XSLT, un processore XSLT. Ve ne sono numerosi, la maggior parte open source. Tra gli altri anche Internet Explorer e Netscape/Mozilla integrano al loro interno un processore XSLT. Questo significa che è possibile pubblicare sul Web documenti XML generici associati a fogli di stile XSL: essi saranno elaborati e trasformati in pagine Web 'standard' direttamente dal browser. Una strategia alternativa consiste nell'effettuare sul server la trasformazione, operazione che si può eseguire sia in modo dinamico (cioè nel momento in cui il client chiede un certo documento XML), utilizzando un XML application server come Cocoon (http://xml.apache.org/cocoon/), sia in modo statico. L'ultimo esponente della famiglia, XSL-FO, infine, è un vero proprio linguaggio di formattazione. Anche XSL-FO adotta la sintassi XML. Possiamo dire che si tratta di un linguaggio di mark-up XML orientato a definire la formattazione e la presentazione grafica di un documento testuale, e a controllare il modo in cui il contenuto testuale e iconografico di un documento si dispone all'interno di una pagina. Il livello di dettaglio che si può conseguire nel controllare l'aspetto visivo di un documento è pari (almeno in teoria) a quello provvisto dai software di impaginazione professionali. Naturalmente il processo di elaborazione è assai diverso. Infatti, come alcuni lettori avranno già immaginato, l'uso di XSL-FO richiede una serie di elaborazioni batch che iniziano con una trasformazione XSLT: per la precisione il documento XML sorgente viene trasformato, mediante un opportuno foglio di stile XSLT, in un documento corrispondente codificato con gli elementi XSL-FO. Quest'ultimo a sua volta va sottoposto a un processore XSL-FO che lo converte in un formato adeguato alla stampa: di norma i processori XSL-FO producono file di output in formati PostScript, PDF, RTF o PCL (il linguaggio usato dalle stampanti HP). Extensible Linking Language e XPointerCome XML estende la capacità di rappresentare documenti sul Web, Extensible Linking Language è stato progettato per incrementare la capacità di creare collegamenti ipertestuali. In un primo momento lo sviluppo di questo linguaggio è stato portato avanti in seno allo stesso gruppo di lavoro del W3C responsabile di XML; ma ben presto si è resa necessaria la formazione di un gruppo apposito, denominato 'XML Linking'. Nel giugno 2001 è stata rilasciata la versione 1.0 dell'XML Linking Language. XLL si divide in due parti: XLink, che si occupa della costruzione dei link, e XPointer, che si occupa della individuazione delle loro destinazioni. Per capire la distinzione funzionale tra i due prendiamo ad esempio un link espresso nella notazione HTML: <a href='http://www.liberliber.it/'>Vai alla Home page di Liber Liber<a> L'intero elemento A, inclusi attributi e contenuto, esprime formalmente un link; il tipo di elemento A preso indipendentemente dalla sua attualizzazione in un documento HTML è un elemento astratto di collegamento ipertestuale; il valore dell'attributo href (nella fattispecie una URL) è un puntatore che esprime la destinazione del link. XLink (http://www.w3.org/TR/xlink/) si occupa di definire gli elementi di collegamento che possono essere utilizzati in un documento XML, le loro caratteristiche e la sintassi in base alla quale vanno esplicitati. Rispetto al semplice costrutto ipertestuale di HTML, XLink costituisce un vero e proprio salto evolutivo. Esso prevede le seguenti tipologie di collegamenti ipertestuali:
Inoltre sono indicati dei sistemi per associare metadati ai link, in modo da qualificarli in base a tipologie (le quali permettono all'autore di predisporre diversi percorsi di esplorazione della rete ipertestuale, o al lettore di scegliere diversi percorsi di lettura) e di specificare il comportamento del browser all'atto dell'attraversamento del link. XPointer invece specifica una sintassi formale per individuare le porzioni di un documento XML a cui un link può puntare. Attualmente le specifiche di XPointer (che sono articolate in quattro distinti documenti, raggiungibili dall'indirizzo http://www.w3.org/XML/Linking) sono candidate a divenire raccomandazioni. Anche in questo caso la capacità espressiva eccede di gran lunga l'elementare meccanismo di puntamento attualmente adottato sul Web. Infatti XPointer permette di individuare specifiche porzioni all'interno di un documento, sino al singolo carattere, senza costringere a inserire delle ancore esplicite. Gran parte della sintassi di indirizzamento è quella di XPath (che è parte anche di un altro linguaggio XQuery, utilizzato per interrogare ed estrarre informazione da collezioni di documenti XML), anche se XPointer introduce alcune ulteriori potenzialità di selezione. Non possiamo in questa sede soffermarci sui dettagli della sua sintassi, ma le possibilità aperte da questo meccanismo sono veramente notevoli. In primo luogo, sarà possibile specificare dei link che abbiano come destinazione punti o porzioni di un documento anche se non si ha il diretto controllo di quest'ultimo (e dunque la possibilità di inserirvi delle ancore). Ma, cosa ancora più notevole, grazie al costrutto dei link esterni di XLink e ai puntatori di XPointer sarà possibile specificare in un file separato (magari manipolabile da parte di più utenti) intere reti di collegamenti tra documenti. Insomma, grazie a questi nuovi linguaggi il Web assomiglierà molto di più all'utopico Xanadu concepito trent'anni fa da Ted Nelson. SMIL e le presentazioni multimediali sincronizzateCome sappiamo, il Web permette la distribuzione di informazioni multimediali tanto in modalità asincrona (come avviene con le pagine Web, i cui costituenti vengono prima inviati dal server al client e poi interpretati e visualizzati) quanto in modalità sincrona (come avviene con i protocolli di streaming). In alcuni casi, tuttavia, sarebbe desiderabile poter correlare lo svolgimento nel tempo di un flusso di informazioni con la presentazione di dati inviati in modalità asincrona o, in generale, sincronizzare sull'asse temporale la distribuzione di dati on-line. Il W3C ha sviluppato e proposto un linguaggio XML che permette di realizzare proprio questa sincronizzazione: si tratta del Synchronized Multimedia Integration Language (SMIL). La seconda versione di SMIL è stata rilasciata in forma definitiva nell'agosto del 2001, e le specifiche sono disponibili sul sito del W3C all'indirizzo http://www.w3.org/TR/smil20/. SMIL è una applicazione XML che consente di integrare una serie di oggetti multimediali in una presentazione sincronizzata. Le informazioni necessarie sono espresse formalmente in un documento XML che consente di descrivere i seguenti aspetti della presentazione:
A tale fine sono provvisti un insieme di elementi XML e di relativi attributi. Usando questa tecnologia è possibile realizzare una applicazione in cui durante la fruizione di un video streaming compaiano immagini e testi in precisi momenti: ad esempio, le immagini di una lezione diffusa mediante un sistema di streaming possono essere affiancate da pagine Web che illustrino i concetti spiegati, esattamente come in aula un docente può fare uso di una lavagna o di una presentazione video. Non a caso il campo di applicazione per eccellenza di questa tecnologia è quello della formazione a distanza, sia in ambito scolastico e universitario sia in ambito professionale. Ma ovviamente le applicazioni possono essere moltissime, dalla promozione di prodotti alle conferenze on-line, dal lavoro collaborativo all'entertainment. Esistono diversi client che hanno implementato SMIL (alcuni dei quali scritti in Java), ma senza dubbio il più importante è RealOne Player, il più diffuso software per la riproduzione di streaming video e audio su Internet, del quale abbiamo già avuto occasione di parlare.
Dare vita alle pagine WebUna pagina Web di norma è un oggetto statico. Tutti i processi di elaborazione che sono necessari a generarla terminano nel momento stesso in cui essa viene visualizzata nella finestra del browser. Anche nel caso dei documenti dinamici la generazione del documento riposa esclusivamente sul lato server. Tuttavia negli ultimi anni sono state sviluppate diverse tecnologie al fine di aumentare le funzionalità interattive di una pagina Web. Alcune si basano sul potenziamento intrinseco delle capacità elaborative del browser, mediante l'uso di semplici linguaggi di programmazione interpretati dal browser stesso. Questi 'linguaggi di script' (le cui istruzioni di norma sono inserite in chiaro all'interno del file HTML) sono in grado di manipolare gli elementi che costituiscono una pagina e di assegnare loro comportamenti interattivi. Grazie a queste tecnologie è possibile realizzare delle pagine Web dotate di comportamenti dinamici e interattivi senza che sia necessario effettuare transazioni HTTP per scaricare nuovi documenti remoti. Altre invece si basano sull'inserimento di veri e propri oggetti software all'interno di una pagina Web. Questi oggetti software - che sono componenti scritti in un vero linguaggio di programmazione e poi compilati o precompilati in formato binario - vengono eseguiti all'interno della finestra del browser (sono dunque parte della pagina Web), ma richiedono la presenza di programmi interpreti esterni. Si tratta di una estensione e generalizzazione del vecchio meccanismo dei plug-in: solo che in questo caso il plug-in è un interprete che esegue programmi, e dunque non è vincolato a una particolare applicazione. Rientrano in questo gruppo gli applet Java e le tecnologie COM e .NET della Microsoft, anche se il dominio di queste architetture non è limitato alla elaborazione client-side. I linguaggi di scriptI linguaggi di script si sono diffusi come strumenti di personalizzazione delle applicazioni di office automation da ormai molti anni. Si tratta in genere di semplici linguaggi di programmazione interpretati, in grado di manipolare alcuni elementi di un programma o di applicare procedure di elaborazione sui dati e sui documenti digitali da esso gestiti. La diffusione della programmazione orientata agli oggetti e di architetture come OLE e OpenDoc, ha reso questi linguaggi sempre più potenti ed efficienti, fino a sostituire in alcuni casi la programmazione con linguaggi compilati tradizionali. La prima applicazione di un linguaggio di script client-side nel contesto del Web si deve a Netscape, con l'introduzione di Javascript. Si tratta di un linguaggio dotato di una sintassi in parte simile a quella del linguaggio Java (su cui ci soffermeremo a breve) e basato su una parziale architettura a oggetti e su un modello di interazione a eventi (come gran parte dei linguaggi simili). Successivamente alla sua prima implementazione, Javascript ha subito diverse revisioni, che hanno creato grandi problemi di compatibilità, contribuendo non poco alla 'balcanizzazione' del Web. In particolare i problemi maggiori erano (e in parte sono tuttora) legati alla diversa definizione degli oggetti su cui è possibile agire nei due browser Netscape ed Explorer (che ha integrato un interprete Javascript, pur cambiando il nome al linguaggio in Jscript, sin dalla remota versione 3). Fortunatamente a mettere ordine in questa situazione è recentemente intervenuta la European Computer Manifacturers Association (ECMA) che ha definito una versione standard di questo linguaggio - la cui diffusione presso gli sviluppatori Web è ormai enorme - denominata ECMAScript. Un secondo linguaggio di script utilizzato nel contesto del Web è VBScript. Si tratta di una sorta di versione semplificata e adattata alla manipolazione di documenti Web del noto linguaggio di programmazione Visual Basic della Microsoft. Naturalmente VBScript viene interpretato esclusivamente da Explorer, e dunque le pagine che lo adottano come linguaggio di script sono in genere collocate su reti intranet. A parte le differenze di sintassi e i limiti di portabilità, entrambi questi linguaggi condividono funzionalità e modalità di impiego. In generale uno script è un piccolo programma (a limite una sola istruzione) il cui codice viene inserito all'interno di una pagina HTML o collegato ad esso, e interpretato dal browser. La funzione di queste piccole applicazioni consiste nell'introdurre estensioni all'interfaccia di una pagina Web o del browser, come pulsanti che attivano procedure, controllo del formato di dati in un campo di immissione o piccoli effetti di animazione (ad esempio, del testo che scorre nella barra di stato del browser). In questo modo è possibile aumentare le potenzialità interattive di una pagina Web senza ricorrere allo sviluppo di plug-in o di applet Java, attività che richiedono una competenza da programmatore. HTML Dinamico e DOMLa diffusione e l'evoluzione dei linguaggi di script ha reso possibile la creazione di pagine Web interattive e l'inserimento di piccoli effetti grafici dinamici. Ma la capacità di produrre delle pagine Web in grado di modificare totalmente il loro aspetto e la loro struttura senza interagire con il server HTTP per ricevere nuovi oggetti o un documento HTML aggiornato, è stata raggiunta solo con l'introduzione della tecnologia conosciuta con il nome di Dynamic HTML, o più brevemente DHTML. In realtà DHTML non esiste come linguaggio in sé. Almeno non nel senso in cui esistono HTML, CSS o uno dei linguaggi di script. Infatti DHTML è il prodotto della convergenza di una serie di tecnologie già esistenti, mediata da un insieme di regole che permettono di usare i fogli di stile e un linguaggio di script al fine di modificare l'aspetto e il contenuto di una pagina Web al verificarsi di un dato evento (ad esempio il click o lo spostamento del mouse, o il passare di un periodo di tempo). Il risultato consiste nella creazione di pagine Web che possono modificarsi senza essere ricaricate dal server: pagine Web dinamiche, appunto. Le tecnologie alla base di DHTML, per la precisione, sono le seguenti:
A dire il vero il cuore di DHTML risiede proprio nel DOM. Esso infatti fornisce una descrizione astratta del documento in termini di oggetti - o meglio, di un albero di oggetti che corrisponde alla struttura logica del documento definita dalla sua codifica HTML o XML - e di interfacce per manipolare tali oggetti: ogni elemento strutturale del documento ha una sua rappresentazione come oggetto nel DOM. Per ciascun oggetto il DOM specifica alcune proprietà, che possono essere modificate, al verificarsi di un evento (il passaggio o il click del mouse, lo scattare di un dato orario, ecc.) mediante una procedura in un determinato linguaggio, e dei metodi, ovvero delle funzioni che ciascun oggetto può effettuare e che possono essere chiamate nell'ambito di un programma. Le utilizzazioni possibili del DOM non sono limitate a DHTML. Ad esempio in ambito XML molti parser generano una rappresentazione del documento in memoria sotto forma di DOM. La tecnologia DHTML ha due vantaggi fondamentali rispetto ai tradizionali sistemi di animazione delle pagine Web (quelli, cioè, che si basano su elaborazioni dal lato server, su plug-in o su programmazione mediante Java o ActiveX). In primo luogo permette di ottenere effetti grafici molto complessi e spettacolari in modo assai semplice. In particolare è possibile avere stili dinamici, che cambiano l'aspetto di una pagina, contenuti dinamici, che ne modificano il contenuto, e posizionamento dinamico, che consente di muovere i componenti di una pagina su tre dimensioni (ottenendo, ad esempio, pagine a strati, o effetti di comparsa e scomparsa di blocchi di testo e immagini). In secondo luogo, permette di conseguire tali effetti con una efficienza e una velocità assai superiori. Quando viene scaricata una pagina dinamica, il client riceve tutti i dati che la compongono, anche se ne mostra solo una parte; gli effetti dinamici dunque usano dati collocati nella memoria locale o nella cache e non debbono fare chiamate al server per applicare le trasformazioni alla pagina corrente. Inoltre l'elaborazione di istruzioni DHTML è assai meno onerosa dal punto di vista computazionale rispetto all'esecuzione di codice Java o ad altri sistemi basati su plug-in. Purtroppo a fronte di questi vantaggi DHTML soffre di un grosso limite: le implementazioni di questa tecnologia che sono supportate dai vari browser (in particolare da Internet Explorer e da Netscape) sono piuttosto diverse. Così una pagina dinamica che funziona sul browser Netscape spesso non viene interpretata correttamente da Explorer, e viceversa. Al fine di standardizzare la manipolazione dinamica di documenti, il W3C ha elaborato una versione di riferimento dell'interfaccia DOM, che fornisce un insieme di specifiche indipendenti da particolari piattaforme o da particolari linguaggi di script per manipolare gli oggetti che compongono un documento HTML o XML (http://www.w3.org/DOM/). Nel momento in cui scriviamo sono in fase di revisione le specifiche della versione 3 del W3C DOM, mentre le varie specifiche DOM level 2 sono divenute raccomandazioni già nel febbraio del 2000. Java e gli appletL'introduzione di Java da parte della Sun29 ha rappresentato una delle maggiori innovazioni nel settore dei sistemi e linguaggi per lo sviluppo di software, soprattutto per la stretta relazione di questo linguaggio con le tecnologie Web. Le origini del linguaggio (che inizialmente era stato battezzato Oak) sono molto singolari: esso fu ideato intorno al 1990 da James Gosling per essere incorporato nei microchip che governano gli apparecchi elettronici di consumo. Per molti anni è rimasto un semplice prototipo, finché intorno al 1995 la Sun ha deciso di farlo evolvere, per proporlo come linguaggio di programmazione per Internet. Le caratteristiche che fanno di Java un linguaggio di sviluppo molto interessante sono diverse. In primo luogo esso adotta il paradigma della programmazione orientata agli oggetti (object oriented): in questo tipo di programmazione, i programmi sono visti come sistemi di oggetti, ognuno dotato di capacità particolari, che possono comunicare tra loro e scambiarsi dati; quando un oggetto ha bisogno di una certa operazione che non è capace di effettuare direttamente (ad esempio scrivere i risultati di un calcolo su un file), non deve fare altro che chiedere i servizi di un altro oggetto. Inoltre ogni oggetto può essere derivato da altri oggetti, ereditando da essi proprietà e comportamenti (metodi). Questo paradigma facilita molto l'attività di programmazione sia perché, in fondo, assomiglia abbastanza al nostro modo di rappresentare il mondo, sia perché permette di riutilizzare gli stessi oggetti in molte applicazioni diverse. In secondo luogo, Java è un linguaggio di programmazione che gode di una notevole portabilità. Questa sua caratteristica deriva dalla modalità in cui un programma viene tradotto in linguaggio macchina ed eseguito. Infatti Java adotta una strategia di 'semicompilazione' in un formato binario (bytecode) indipendente dalla piattaforma. Il programma semicompilato viene tradotto nel linguaggio macchina specifico di una singola piattaforma (sistema operativo/processore), in fase di esecuzione da un particolare genere di interprete, detto 'macchina virtuale'. La Java Virtual Machine (JVM) fornisce una rappresentazione astratta di un computer che il programma utilizza per effettuare tutte le operazioni di input e output. È poi la JVM che si preoccupa di tradurre tali operazioni in istruzioni macchina per il computer sul quale è installata, comunicando con il sistema operativo o direttamente con il processore. In questo modo un programma scritto in Java può essere eseguito indifferentemente su ogni piattaforma per cui esista una JVM, senza subire modifiche. Una ulteriore caratteristica di Java è il fatto di essere stato progettato appositamente per lo sviluppo di applicazioni distribuite, specialmente con l'uscita delle estensioni JavaBean. Questo significa che un'applicazione Java può essere costituita da più moduli, residenti su diversi computer, in grado di interoperare attraverso una rete telematica. Il sistema di sviluppo Java, completo di compilatore, macchina virtuale e librerie, viene distribuito gratuitamente dalla Sun per numerose piattaforme (Windows, Mac OS, Linux, Solaris). Per chi è interessato, il sito di riferimento è all'indirizzo Web http://www.javasoft.com/30. L'ultima versione del linguaggio e del relativo sistema di sviluppo (battezzato Java 2 Standard Edition) è la 1.4.1. Naturalmente esistono altre implementazioni di JVM, alcune delle quali open source, e recentemente Java è entrato anche nel settore per il quale era stato originariamente concepito, quello dei piccoli elettrodomestici di consumo: applicazioni Java sono così utilizzabili, ad esempio, su un numero crescente di telefonini cellulari, inclusa la quasi totalità dei telefonini di terza generazione (UMTS) disponibili nel momento in cui scriviamo. Le caratteristiche tecniche di Java ne fanno un ottimo candidato a divenire la piattaforma di riferimento per lo sviluppo di applicazioni Internet, sebbene la Microsoft abbia nel corso degli anni proposto numerose architetture concorrenti31. Questo vale soprattutto per le applicazioni server, il settore su cui la Sun si è concentrata negli ultimi anni. Tuttavia sin dalla sua introduzione Java è stato utilizzato anche per la creazione di applicazioni e componenti software da eseguire sul lato client. Queste versioni Web dei programmi Java, che possono essere inserite direttamente all'interno di una pagina Web, si chiamano applet. Ogni volta che il documento ospite viene richiesto da un browser, l'applet viene inviato dal server insieme a tutti gli altri oggetti che costituiscono la pagina. Quando il browser riceve un applet effettua una chiamata alla JVM, che si occupa di eseguire il codice. In questo modo le pagine Web possono animarsi, integrare suoni in tempo reale, visualizzare video e animazioni, presentare grafici dinamici, trasformarsi virtualmente in ogni tipo di applicazione interattiva. Nella figura 119 vediamo un esempio di applet Java eseguito in una finestra di Internet Explorer; si tratta di un programma che simula il funzionamento di una 'macchina di Turing' (lo trovate alla URL http://www.igs.net/~tril/tm/tm.html)32.
I vantaggi di questa tecnologia rispetto ai sistemi basati su plug-in (come avviene ad esempio per Flash) sono evidenti. Questi ultimi, infatti, sono delle normali applicazioni che vanno prelevate (magari direttamente da Internet) e installate appositamente. Solo allora possono esser utilizzate. E deve essere l'utente a preoccuparsi di fare queste operazioni, con le relative difficoltà. Ma soprattutto i plug-in sono programmi compilati per un determinato sistema operativo (e per un determinato browser!), e non funzionano sulle altre piattaforme: un plug-in per Windows non può essere installato su un computer Mac o Unix. Con Java questi limiti vengono completamente superati. Infatti i programmi viaggiano attraverso la rete insieme ai contenuti. Se ad esempio qualcuno sviluppa un nuovo formato di codifica digitale per le immagini, e intende utilizzarlo per distribuire file grafici su World Wide Web, può scrivere un visualizzatore per quel formato in Java e distribuirlo insieme ai file di dati. Ogni browser dotato di interprete Java sarà in grado di mostrare le immagini codificate nel nuovo formato. Inoltre lo stesso codice funzionerebbe nello stesso modo su ogni piattaforma per la quale esista una JVM (e un browser un grado di intergire con essa). Con l'introduzione di Java, il potere di 'inventare' nuove funzionalità e nuovi modi di usare Internet passa nelle mani di una comunità vastissima di programmatori, che per di più possono sfruttare l'immenso vantaggio rappresentato dalla condivisione in rete di idee, di soluzioni tecniche, di moduli di programma. Le potenzialità innovative di Java vanno ben oltre l'introduzione di semplici applicazioni dimostrative all'interno delle pagine Web. Un applet infatti è un programma vero e proprio, che può svolgere in teoria qualsiasi funzione, anche le più complesse: database, word processor, foglio di calcolo, programma di grafica, gioco multiutente. Gli sviluppi di questo genere di applicazioni distribuite potranno avere notevoli ripercussioni sul modo in cui il software viene utilizzato, specialmente nell'ottica della diffusione di tecnologie Intranet e del network computing, uno slogan coniato dal CEO della Sun Scott McNealy per indicare il nuovo paradigma di informatica distribuita. Un aspetto particolare legato alla tecnologia Java è quello della sicurezza informatica. Per evitare problemi agli utenti, l'interprete del linguaggio è dotato di potenti sistemi di sicurezza, che impediscono a un programma di interagire direttamente con le componenti più delicate del sistema operativo. In questo modo, dovrebbe essere limitata la possibilità di scrivere e diffondere attraverso la rete pericolosi virus informatici. In effetti, queste protezioni rendono estremamente difficile la progettazione di applet veramente dannosi - in particolare per quanto riguarda azioni come la distruzione dei dati sul nostro disco rigido o simili. Tuttavia, come ci si poteva aspettare, qualcuno ha finito per interpretare questa difficoltà come una vera e propria sfida, e la corsa alla programmazione di quelli che sono stati efficacemente denominati 'hostile applets' è iniziata. Né è mancato qualche risultato: si è visto che, nonostante le precauzioni, un applet Java può riuscire a 'succhiare' risorse dal sistema fino a provocarne il blocco. Il danno effettivo non è di norma troppo rilevante (al limite, basta spegnere e riaccendere il computer), ma naturalmente non va neanche sottovalutato, soprattutto nel caso di un accesso a Internet attraverso grossi sistemi, il cui blocco può coinvolgere altri utenti. Le alternative Microsoft: da COM e ActiveX a .NETSin dalla sua prima comparsa, la piattaforma Java ha suscitato notevoli apprensioni nel gigante mondiale del software. Sebbene Microsoft abbia implementato una JVM assai presto33, integrandola con Explorer, è andata continuamente alla ricerca di una alternativa che le consentisse di estendere il suo predominio commerciale anche nel settore degli strumenti di sviluppo per le applicazioni Internet. La prima di queste alternative è consistita nell'architettura Component Object Model (COM34) e nei controlli ActiveX. Il sostanziale fallimento di questa tecnologia (eccezion fatta per le applicazioni di casa Microsoft) ha comportato di fatto il suo progressivo abbandono a favore di una nuova piattaforma introdotta nel 2002 e battezzata .NET. COM è l'evoluzione di OLE (Object Linking and Embedding), la tecnologia che permetteva ai programmi in ambiente Windows di comunicare tra loro e di creare documenti compositi35. Si tratta di una architettura che consente a componenti software di interagire e di scambiarsi dati e funzioni sia localmente sia in ambiente distribuito. Questa architettura svolge un ruolo centrale nel funzionamento dei sistemi operativi più recenti e di numerosi applicativi di casa Microsoft. Ma tra le sue applicazioni si annovera anche la possibilità di incorporare all'interno delle pagine Web oggetti attivi e di controllarne il comportamento e l'interazione con il browser. Tali oggetti, che sono stati battezzati controlli ActiveX, sono funzionalmente simili agli applet Java, ma ovviamente possono essere eseguiti esclusivamente da un browser che supporti COM, ovvero solo da Microsoft Internet Explorer.
Un controllo ActiveX può svolgere qualsiasi funzione: interpretare e visualizzare file multimediali, accedere a un database, collegarsi a un server IRC, fornire funzioni di word processing, fino a divenire un programma vero e proprio con una sua interfaccia utente. Quando Internet Explorer riceve una pagina Web che integra dei controlli, li esegue automaticamente, ereditandone i comandi e le funzioni. Un esempio di utilizzazione di ActiveX è il sistema di aggiornamento on-line delle recenti versioni di Windows. Quando si accede al sito Windows Update, infatti, Internet Explorer scarica un controllo ActiveX (Microsoft Active Setup) che interagisce con il sistema operativo e permette di scaricare e installare gli aggiornamenti direttamente dalla rete, controllando automaticamente l'eventuale rilascio di aggiornamenti critici. Oltre a funzionare nel contesto di pagine Web, gli oggetti ActiveX possono essere eseguiti da ogni applicazione dotata di supporto COM, e cioè la maggior parte dei più evoluti programmi per la piattaforma Windows. Simmetricamente, un software dotato di supporto COM è in grado di visualizzare e modificare i documenti prodotti dalle applicazioni Office della Microsoft, e in generale da tutti i programmi che rispondono alle specifiche OLE 2. Come dicevamo in apertura, nonostante gli sforzi di Microsoft, l'architettura COM non ha riscosso il successo sperato. Il gigante di Redmond pensava di vincere la battaglia con la piattaforma Java contando sul fatto che la maggior parte degli sviluppatori e delle software house conoscevano molto bene la tecnologia OLE, di cui COM era una semplice evoluzione, e linguaggi di programmazione come C++ e Visual Basic. Inoltre i componenti COM, essendo compilati, sono decisamente più efficienti e veloci nell'esecuzione rispetto ai programmi Java. Ma proprio la natura proprietaria di gran parte delle tecnologie COM ne ha limitato l'accoglienza. Dalla constatazione di questo fallimento nasce la nuova piattaforma orientata allo sviluppo di applicazioni distribuite realizzata ed enfaticamente presentata da Microsoft nel 2002: .Net36. Dal punto di vista strutturale e funzionale .Net è assai simile a Java. Infatti il cuore dell'intera architettura è costituito dalla Common Language Infrastructure (CLI), una macchina virtuale e una libreria di funzioni standard in grado di eseguire (con una tecnica detta Just in Time Compilation) un codice precompilato in un formato denominato Microsoft Intermediate Language (MSIL). La creazione di un codice eseguibile MSIL può essere fatta a partire da programmi scritti in qualsiasi linguaggio per cui esista un compilatore .Net. La Microsoft ha realizzato sistemi di sviluppo per i seguenti cinque linguaggi, che condividono librerie di funzioni e classi di oggetti:
Sono comunque disponibili compilatori per numerosi altri linguaggi, anche in versioni open source. .NET eredita a un tempo le funzioni di COM (e di ActiveX) e quelle dei vari ambienti di sviluppo software di casa Microsoft. Permette dunque di sviluppare sia applicazioni autonome sia applicazioni distribuite e, per queste ultime, sia i moduli client sia, o meglio soprattutto, i moduli server. In effetti questa tecnologia si rivolge specificamente al mondo delle applicazioni Web e dei Web service, uno dei settori su cui si concentra attualmente l'attenzione del mercato. Per quanto riguarda la piattaforma, il Framework .Net ufficiale per Windows 2000/XP è disponibile gratuitamente sul sito Microsoft. Ma esiste anche una implementazione open source dell'architettura .Net in ambiente Linux, battezzata Mono (http://www.go-mono.com/). Dai contenuti dinamici ai Web serviceCome abbiamo anticipato in apertura, uno dei settori in cui le tecnologie Internet hanno visto una profonda evoluzione è quello della fornitura di servizi e applicazioni avanzate sul Web. In questo settore possiamo collocare una famiglia di soluzioni e piattaforme tecnologiche i cui confini reciproci sono alquanto sfumati:
La differenza tra queste categorie è funzionale piuttosto che tecnologica. Nelle prime due rientrano le piattaforme destinate ad automatizzare la generazione di documenti Web. Nelle seconde le piattaforme orientate alla creazioni di vere e proprie applicazioni distribuite che possono, ma non debbono necessariamente, avere interfacce utente (ad esempio molti componenti di un servizio di commercio elettronico non richiedono intervento umano, sebbene debbano cooperare). I sistemi per la gestione dinamica dei contenuti WebI sistemi per la generazione dinamica dei contenuti sono tecnologie che consentono di produrre pagine Web nel momento in cui un client le richiede. I documenti dunque non esistono come oggetti digitali autonomi sul server, ma vengono assemblati e codificati in HTML o XML mediante l'esecuzione sul server di procedure automatiche. La tecnica più comune adottata in queste applicazioni si basa sull'uso di linguaggi di script interpretati ed eseguiti nativamente dal server Web o da un modulo software (detto application server) che si affianca ad esso. Le più diffuse piattaforme di scripting server side sono Active Server Pages (ASP), implementata nei server Web Microsoft; PHP (un acronimo ricorsivo che sta per PHP: Hypertext Preprocessor), legata al server Web open source Apache (ma esistono diverse applicazioni che consentono di eseguire PHP anche con server Microsoft); Cold Fusion (il cui linguaggio si chiama Cold Fusion Markup Language), basata sull'omonimo application server sviluppato dalla Allaire e recentemente acquisito da Macromedia; Java Server Pages (JSP), un linguaggio basato su Java che viene interpretato dai vari application server Java. In generale questi linguaggi consentono di inserire segmenti di codice all'interno di uno scheletro (template) di documento marcato in linguaggio HTML. Quando la pagina viene richiesta, il codice viene eseguito e il documento risultante inoltrato al client. Poiché gran parte dei contenuti viene archiviata in un database, l'esecuzione del codice consiste di norma nell'invio di uno o più query al database management system al fine di estrarne i dati rilevanti, che vengono successivamente codificati in HTML. Ad esempio, in un catalogo di prodotti on-line, le informazioni relative a ogni singolo prodotto sono di norma contenute in un database, dal quale vengono estratte e inserite all'interno di marcatori HTML. Una soluzione alternativa si basa sull'uso di XML e sull'esecuzione di trasformazioni XSLT sul lato server. In questo caso i file XML possono essere statici o a loro volta possono essere generati dinamicamente. Con la crescita delle dimensioni dei siti Web, queste tecniche sono state applicate anche nella creazione e gestione dei contenuti. Nascono così i sistemi di content management (CMS) veri e propri, che abbiamo già incontrato nel capitolo dedicato ai weblog. Tali sistemi permettono di creare maschere di inserimento dei dati basate sul Web o su applicazioni client ad hoc, mediante le quali gli autori aggiungono contenuti a un sito in maniera estremamente semplice, senza preoccuparsi della loro codifica in HTML o XML e della loro impostazione grafica. Inoltre i CMS forniscono servizi avanzati per la manutenzione complessiva del sito e per la gestione dei flussi di processo e delle autorizzazioni. Ormai gran parte dei grandi siti e portali (pubblici e aziendali) adottano sistemi CMS, e - come abbiamo visto - tecnologie simili si stanno rapidamente diffondendo anche nel settore del personal publishing. Gli application server e i Web serviceSebbene il Web sia nato come architettura per la disseminazione di contenuti digitali multimediali, la sua rapida evoluzione ne ha reso evidente l'efficacia per la fornitura di servizi e applicazioni avanzate, sia in ambito Internet sia nel contesto di sistemi informativi aziendali in architettura intranet/extranet. La maturazione dei protocolli e dei formati di base, infatti, ha reso possibile implementare con tecnologie Web tutti quei requisiti di sicurezza, efficienza e affidabilità che tradizionalmente erano assicurati solo da piattaforme chiuse e proprietarie. I domini in cui le applicazioni Web vengono ormai ampiamente utilizzate sono numerosi e variegati: commercio elettronico B2C e B2B, home-banking e servizi finanziari, e-government, editoria digitale, marketing e servizi post-vendita, groupware e knowledge management... Naturalmente quando si parla di applicazioni Web non ci si riferisce solo alla gestione dei contenuti (sebbene questa attività ne sia parte integrante), ma alla esecuzione di procedure complesse, spesso delicate o, per usare il gergo degli addetti ai lavori, mission critical, che possono richiedere l'integrazione tra sistemi software eterogenei preesistenti. Prendiamo ad esempio un sistema di commercio elettronico: di norma esso prevede un componente che gestisce l'interfaccia Web (il negozio on-line), a sua volta appoggiato su un database in cui sono archiviati i dati dei singoli prodotti; un componente per la gestione del magazzino che può interagire con servizi B2B dei fornitori; un componente di gestione degli ordini che si deve integrare con il sistema di fatturazione e contabilità aziendale e deve comunicare con i servizi di pagamento con carta di credito dei diversi gestori. Ciascuno di questi componenti naturalmente deve interagire, mediante una rete locale o direttamente via Internet, con uno o più tra gli altri componenti, possibilmente senza alcuna mediazione da parte di operatori umani. E inoltre può accadere (anzi di norma accade) che parte di questi componenti sia già presente in un'azienda (ad esempio il sistema per la gestione del magazzino, o quello per la contabilità); il che pone il problema, non sempre di facile soluzione, di farli interagire in modo trasparente con le nuove applicazioni. Questa descrizione, piuttosto sommaria, ci permette di apprezzare la complessità che può nascondersi dietro l'etichetta di 'applicazione Web', e dietro servizi on-line che ormai moltissimi utenti usano comunemente. E parallelamente ci consente di comprendere perché il settore delle piattaforme software per creare e gestire servizi e applicazioni Web susciti tanto interesse tra le aziende informatiche. Le tecnologie utilizzate a questo fine sono diverse. Nei casi in cui le architetture di sistema sono abbastanza semplici, esse si basano sui medesimi sistemi di programmazione server side che abbiamo visto nel paragrafo precedente. Ma non appena la complessità cresce sono necessarie soluzioni assai più evolute. In questa arena si gioca il confronto, cui abbiamo già accennato, tra la piattaforma Java e la nuova piattaforma Microsoft .Net. La piattaforma Java - che gode di un vantaggio di posizione derivato dal fatto che è disponibile da diversi anni - si basa sullo sviluppo di applicazioni in linguaggio Java o JSP (dette servlet), che vengono eseguite da specifici server applicativi basati sull'architettura J2EE. Tra questi ricordiamo prodotti commerciali come IBM WebShpere e BEA Web Logic, e prodotti open source come Tomcat e JBoss (ma ve ne sono molti altri). Questi prodotti possono cooperare con diversi server HTTP, anche se spesso sono legati strettamente a uno in particolare. Naturalmente i vantaggi e gli svantaggi di Java, su cui ci siamo già soffermati, valgono anche per queste piattaforme applicative: si tratta di sistemi multipiattaforma e, almeno in teoria, un servlet può girare indifferentemente su ciascuna di esse, indipendentemente dal sistema di base e dall'hardware utilizzato. Ma al contempo l'efficienza e la velocità di esecuzione non sono sempre adeguate, e possono variare notevolmente a seconda dell'hardware sottostante. La piattaforma .Net, che come si è accennato è stata introdotta da Microsoft nel 2002, è invece strettamente legata ai sistemi operativi Windows di classe server. Le nuove versioni di questi sistemi, battezzati Windows Server 2003, integrano in modo nativo il Framework .Net e ne rappresentano la migliore (anche se non l'unica) implementazione. Un possibile vantaggio di .Net risiede nella capacità di supportare numerosi linguaggi di programmazione per lo sviluppo, e di poter integrare oggetti software preesistenti. Esistono anche altre piattaforme per lo sviluppo di server applicativi: tra queste ricordiamo in particolare Zope (http://www.zope.org/), una architettura completamente open source che si basa sul linguaggio di programmazione Python, particolarmente apprezzato tra gli sviluppatori per la sua eleganza e linearità. In questa sede non possiamo approfondire i dettagli tecnici che caratterizzano queste diverse soluzioni. Prima di terminare il paragrafo, tuttavia, è opportuno soffermarci su un concetto connesso a quello di applicazione Web ma non perfettamente coincidente con esso: ci riferiamo al concetto di Web service. Abbiamo visto come la creazione di servizi avanzati sul Web di norma richieda l'integrazione e l'interoperabilità tra molteplici applicazioni Web. Chiaramente se un certo servizio si basa su una architettura software sviluppata ex novo, nel contesto di un progetto unitario condotto da una singola struttura, il problema dell'interoperabilità può essere risolto alla radice. Ma nella realtà queste condizioni difficilmente si verificano. E in generale può succedere - e, se le previsioni degli analisti si dimostreranno giuste, sempre più spesso succederà - che una certa azienda metta a disposizione (in affitto) dei propri clienti servizi applicativi specializzati, accessibili tramite i protocolli Web. Il concetto di Web service nasce proprio per fornire una soluzione standardizzata e di (relativamente) semplice implementazione al problema dell'integrazione tra applicazioni distribuite, sia in ambiente Intranet sia in ambiente Internet. Un Web service infatti è un'applicazione che può scambiare dati e processi con altre applicazioni basandosi sulle seguenti tecnologie standard:
Poiché sia WSDL sia SOAP, il cuore dell'architettura, si basano sulla sintassi XML, questo genere di servizi è comunemente denominato anche XML Web service. Tutte le maggiori piattaforme applicative, incluse ovviamente Java e .Net, implementano i protocolli per la creazione di Web service. Su questa tecnologia - considerata strategica da molti analisti - sono infatti rivolte le attenzioni di tutti i protagonisti del mercato ICT, per le ragioni su cui ci siamo già soffermati in apertura di capitolo. Verso il Web SemanticoChiudiamo questa nostra rassegna sull'universo complesso e articolato delle tecnologie Web con uno sguardo verso il futuro: il sogno del Web Semantico37. Abbiamo usato il termine sogno, anche se alcuni dei mattoni di questa idea sono già disponibili, sia perché si è ancora ben lontani dalla costruzione dell'intero edificio, sia perché, quando e se questa avverrà, si tratterà di una rivoluzione radicale del modo di interagire con e sulla rete. Per usare le parole del suo ideatore, «the Semantic Web is an extension of the current Web in which information is given well-defined meaning, better enabling computers and people to work in cooperation»38. In breve, l'idea alla base del Web Semantico consiste nell'associare alle risorse informative disponibili in varie forme sul Web una descrizione formale del loro significato, cosicché un programma possa elaborare tale informazione facendosi guidare dalla sua semantica (cioè tenendo conto di che cosa essa significhi), dedurne conseguenze, e generare automaticamente nuove informazioni. Le ricadute applicative di questo progetto sono numerose, e vanno dalla creazione di motori di ricerca semantici alla individuazione di risposte a problemi e domande (del tipo di quelli che citavamo nel paragrafo introduttivo), dalla interazione multilinguistica uomo-macchina e macchina-macchina alla creazione di applicazioni Web 'intelligenti'. Le componenti che dovranno contribuire alla costruzione del Web Semantico sono numerose, ma le principali sono le seguenti:
Le URI, come sappiamo, sono le formule che consentono di identificare le risorse sulla rete. Ogni risorsa - dal singolo documento alle sue parti, a oggetti ed entità in essi menzionate, a collezioni di documenti - deve avere un suo identificativo URI, affinché possa essere univocamente individuata nello spazio informativo costituito dal Web. Una volta che una risorsa può essere identificata, saremo in grado di esprimere su di essa asserzioni che ne descrivano il contenuto, o che esprimano ciò che noi pensiamo su tale contenuto, e in generale che ne specifichino proprietà da vari punti di vista. Queste asserzioni sono informazioni che si riferiscono ad altre informazioni, ovvero metadati. Con il termine metadati (dati sui dati), come abbiamo già avuto occasione di ricordare, si indica appunto un insieme strutturato di informazioni che descrivono una o più risorse informative sotto un certo punto di vista. I metadati hanno una funzione molto importante nell'individuazione, nel reperimento e nel trattamento delle informazioni. Un classico esempio è costituito dai riferimenti bibliografici di una pubblicazione (titolo, autore, editore, ecc.). Essi in primo luogo identificano una pubblicazione e in secondo luogo sono necessari al reperimento del testo nel 'sistema informativo' biblioteca. Naturalmente, affinché i metadati siano utilizzabili non solo dagli esseri umani ma anche dai computer, è necessario che essi siano espressi in un linguaggio che sia comprensibile alla macchine, sia dal punto di vista sintattico sia da quello semantico. È questo il fine del Resource Description Framework (RDF). Si tratta di un metalinguaggio dichiarativo basato sulla sintassi XML (ma sono state sviluppate altre notazioni più compatte per esprimere asserzioni RDF, come Notation 3, http://www.w3.org/DesignIssues/Notation3), che permette di rappresentare formalmente i metadati associati a una risorsa Web (dal singolo oggetto costituente una pagina a interi siti) sotto forma di asserzioni soggetto-predicato-oggetto, dove i predicati possono esprimere formalmente proprietà di e relazioni tra risorse. L'architettura prevista da RDF si divide in due parti: la prima, denominata Resource Description Framework (RDF) Model and Syntax Specification - le cui specifiche sono state rilasciate come raccomandazioni definitive nel febbraio 1999 e sono disponibili su http://www.w3.org/TR/REC-rdf-syntax - definisce la sintassi per descrivere i metadati associati a una risorsa in una RDF Description. Quest'ultima è un documento XML, costituito da una serie di dichiarazioni che associano dei valori alle proprietà che vogliamo attribuire alla risorsa (ad esempio, la proprietà 'titolo', la proprietà 'autore', ecc.). Tuttavia RDF non fa alcuna assunzione circa il vocabolario specifico delle proprietà che si possono attribuire e delle relazioni tra tali proprietà. Anzi, essa è progettata esplicitamente affinché siano gli stessi utilizzatori a definire formalmente uno schema logico di tale vocabolario, in modo tale da non imporre alcuna limitazione a priori al tipo di asserzioni esprimibili. A tale fine occorre definire un RDF Schema, la seconda parte dell'architettura RDF, in base alla sintassi formale definita nel documento RDF Vocabulary Description Language 1.0: RDF Schema (attualmente allo stato di 'Working Draft': http://www.w3.org/TR/rdf-schema). Una volta che uno schema è stato definito formalmente e pubblicato, chiunque può adottarlo e utilizzarlo per costruire descrizioni RDF dei propri documenti. Naturalmente, poiché potranno esistere numerosi schemi - basati su diverse concettualizzazioni di particolari domini, su diverse nomenclature e su diverse lingue - occorrerà un sistema per specificare le relazioni logico-semantiche (equivalenza, specificazione, generalizzazione, istanziazione, ecc.) tra i termini di un medesimo schema e soprattutto di schemi diversi. Ad esempio, in uno schema la relazione di 'autorialità' potrà essere indicata con il termine 'author' - che fa parte della classe 'creator' - in funzione di soggetto, il cui oggetto è una certa risorsa; in un altro potremmo avere che il soggetto è il testo di cui si predica che 'è scritto da' un esponente della classe 'responsabili intellettuali' caratterizzato dalla proprietà 'primario'. Evidentemente si sta parlando dello stesso insieme di individui e relazioni (dello stesso dominio), ma in modo diverso. Le ontologie formali sono un sistema ideato per definire formalmente domini concettuali e indicare in che modo essi sono espressi da schemi logici e nomenclature differenti39. Esistono numerosi linguaggi formali per specificare ontologie. In particolare nel contesto del Web Semantico si segnalano il DARPA Agent Markup Language (DAML+OIL, http://www.daml.org/), un linguaggio stabile e relativamente utilizzato, e il Web Ontology Language (OWL) in corso di sviluppo presso il W3C sulla base dello stesso DAML e di RDF; entrambi adottano come sintassi standard XML. Una volta che un insieme di risorse sia stato descritto mediante asserti RDF, e che un apparato di ontologie formalizzate abbia specificato le relazioni concettuali soggiacenti a tali descrizioni, è possibile usare dei sistemi di deduzione logica automatica o di euristiche (i motori inferenziali) per elaborare tale informazione semantica, trarne conseguenze, e risolvere problemi. E dunque un agente software dotato di queste capacità inferenziali potrebbe finalmente mostrare parte di quei comportamenti 'intelligenti' cui ci hanno abituato i romanzi cyberpunk. In realtà i problemi teorici - studiati da oltre cinquanta anni nell'ambito della logica, dell'informatica teorica e dell'intelligenza artificiale - e le difficoltà pratiche di implementazione associate a questo genere di applicazioni sono innumerevoli e di non facile soluzione. Inoltre l'idea del Web Semantico potrà essere messa in pratica solo se ad essa collaborerà l'intera comunità di creatori e utenti delle risorse di rete: sarebbe impensabile, infatti, cercare di associare informazioni semantiche a tutte le risorse Web con una iniziativa unica e centralizzata. Per questi motivi, molti esperti nutrono non pochi dubbi sul fatto che l'architettura del Web Semantico - almeno nella sua versione più ambiziosa - potrà mai trasformarsi da sogno a realtà. Ma in fondo solo dieci anni fa, nei laboratori del Cern di Ginevra, anche il World Wide Web così come oggi lo conosciamo era solo un sogno nella mente di Tim Berners-Lee... Note
|
 |
|||||||||
|
|
|
|||||||||
 |
 |
 |
|||||||||
| Inizio pagina |  |
 |